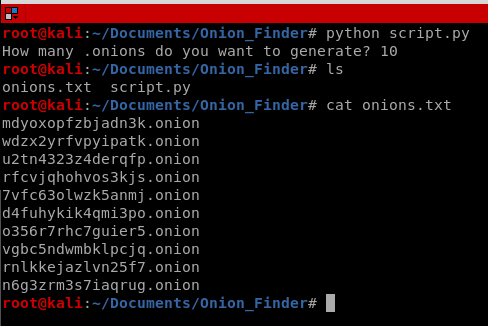
Identifying .onion websites can be problematic, especially if they’re “member only” or not posted about on frequently used Internet locations, such as 4Chan or Reddit. Now, there is the Hunchly report which you can subscribe to at http://hunch.ly/darkweb-osint/ but with myself being unsure how that report identifies new .onion sites, I was tinkering with a way to attempt to identify sites myself.
Onion addresses are the first 16 characters of the public key associated with the .onion site, consisting of the lowercase letters a through z and the numbers 2 through 7. Granted, there are some .onion sites that utilize longer addresses but for now these aren’t the norm. Thus, we can create a short Python script to generate random .onion sites we can later lookup.
import random, string
file = open("onions.txt", "w")
times = input("How many .onions do you want to generate? ")
for i in range(times):
x = ''.join(random.choice('234567abcdefghijklmnopqrstuvwxyz') for i in range(16))
y = x + ".onion"
file.write(y)
file.write("\n")
file.close()
Now that we have a script that will create .onion sites, we need a simple way to determine if the site is up. Since Tor does not support the ICMP protocol, we can’t simply ping the site. We can use the CURL command, however, and get a HTTP status code that will tell us if the website is up, or is being redirected, or simply doesn’t exist.
To test this we’ll use the New York Times .onion address: https://www.nytimes3xbfgragh.onion/
We can then use the following curl command: curl -o /dev/null -s -w “%{http_code}\n” –socks5-hostname localhost:9050 https://www.nytimes3xbfgragh.onion
The command has the following options:
- -o to specify an output location (in our case /dev/null because we don’t want to save it)
- -s to run in silent mode, don’t tell us error messages and the like
- -w to write information to standard out
- –socks5-hostname to point to the proxy we’re utilizing for Tor
To break down the command without the -o, -w, or -s options, our results look like this:
And that’s only part of it. So let’s do a curl and re-direct the output to a .txt file: curl –socks5-hostname localhost:9050 https://www.nytimes3xbfgragh.onion > file.txt

Now, we’d think we might be able to grep for “http_code” or something similar from the resulting file, but the status code we’re looking for isn’t stored within there. So yea, the previous step was pretty pointless. What we want is the http response code that is received, which wouldn’t be stored within the .html file itself. That’s why we need the -w option with the -w “%{http_code}\n” More information on this option can be found in the manpage for curl: https://curl.haxx.se/docs/manpage.html
Thus, when we run our code we get this:

A beautiful HTTP status code of 200, which according to this page means we are good to go.
Now, to only combine the script with the curl command…..
Update:
So, putting commands like curl into Python scripts is not ideal, because there are libraries for that, like the Requests library: https://requests.readthedocs.io/en/master/
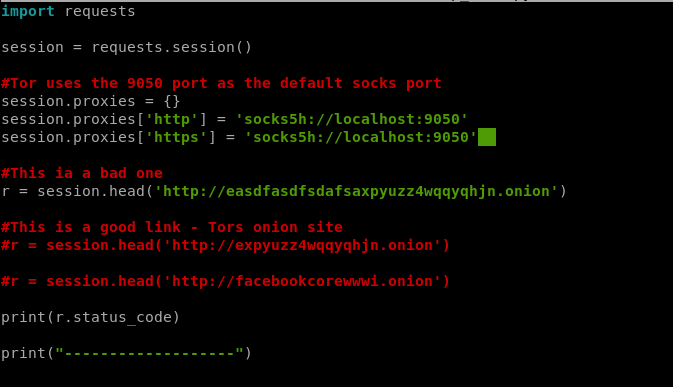
We’re going to start by writing a new script for now, one that just gets the HTTP status code for .onion sites. We’ll use some .onion sites that we know work, like Facebook and Tor, as well as one we made up to make sure we’re good to go. Let’s start with this code:
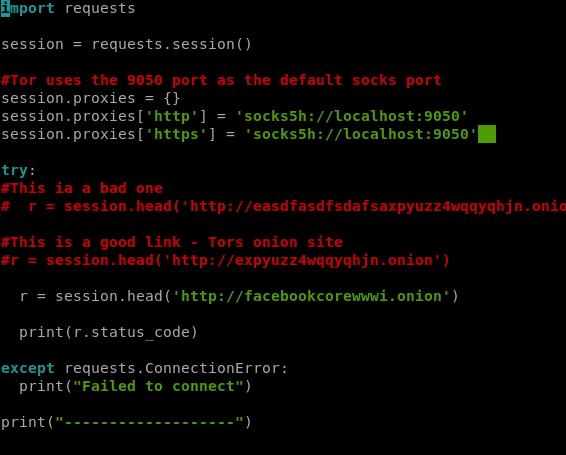
import requests
sessions = requests.session()
#Tor uses the 9050 port as the default Socks port
session.proxies = {}
session.proxies['http'] = 'socks5://localhost:9050'
session.proxies['https] = 'socks5://localhost:9050'
r = session.head('http://facebookcorewwwi.onion')
print(r.status_code)And when run, looks like this:

So we now have some code that will utilize the SOCKS5 proxy to request the HTTP status code from a .onion website, and in this case it returned us 302, which means “Found”. Sweet!
Now, let’s test a “bad” site and see what happens. I’ll use a .onion I made up by mashing the keyboard.
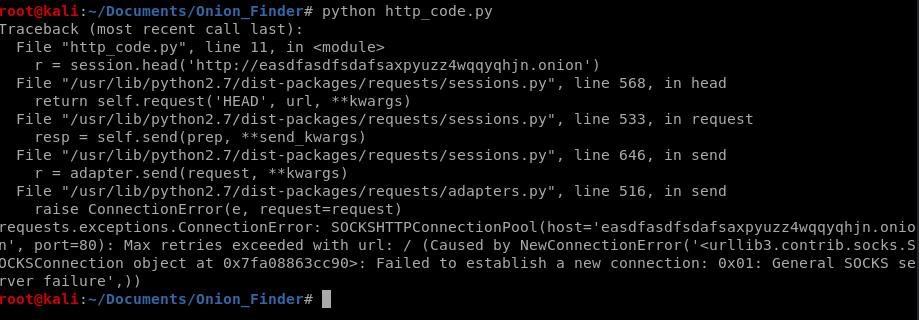
And we get a weird error. Which I’d expect, but I’d like it to be handled more gracefully. So let’s do that with try and except.
And we see in the results above I tried it twice, once with a bad link and once with a good one, and got the results I expected.
Now, we need to start putting everything all together. Ideally, we want our end result to generate a .onion site, see if it’s live, and if it is save those results to a document of some type. In this case, probably a CSV. But first, let’s figure out which HTTP codes we care about.
We can do this with a set in Python. So our set is going to look like this
http_codes = {200, 201, 202, 203, 204, 205, 206, 207, 208, 226,
300, 301, 302, 303, 304, 305, 306, 307, 308}Now, there might be a more efficient way to do it, but that’s what I’m starting with. Next, we add an if statement.
if code in http_codes:
print("True")
print(code)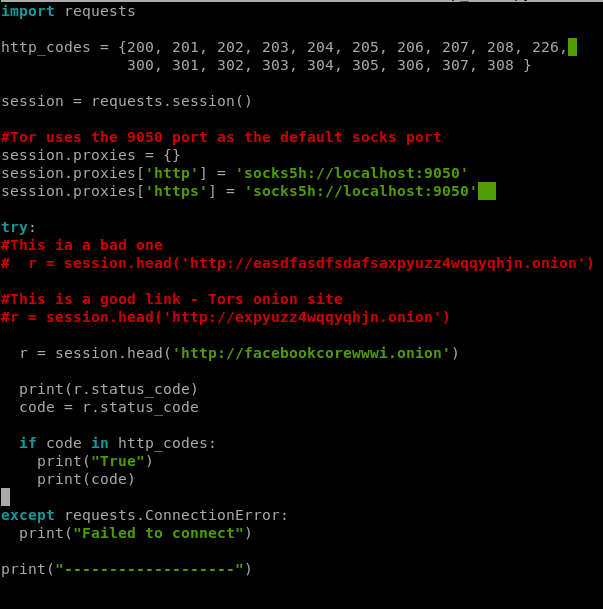
And this should tell us if our HTTP code is in a list of codes that are indicative of a website being up. Rock on!

Next, we need to write our results to some kind of file. Let’s use a .csv, so create one called my_generated_list.csv
We’ll use the standard Python practice of opening it up in append mode…
linksfile = open("my_generated_list.csv", "a")
…and then writing the information we need to the file…
linksfile.write("test" + "," + str(code) + "\n"I used “test” here as a place holder until we fill it with our randomly generated URL. Thus, our finished code looks like this.
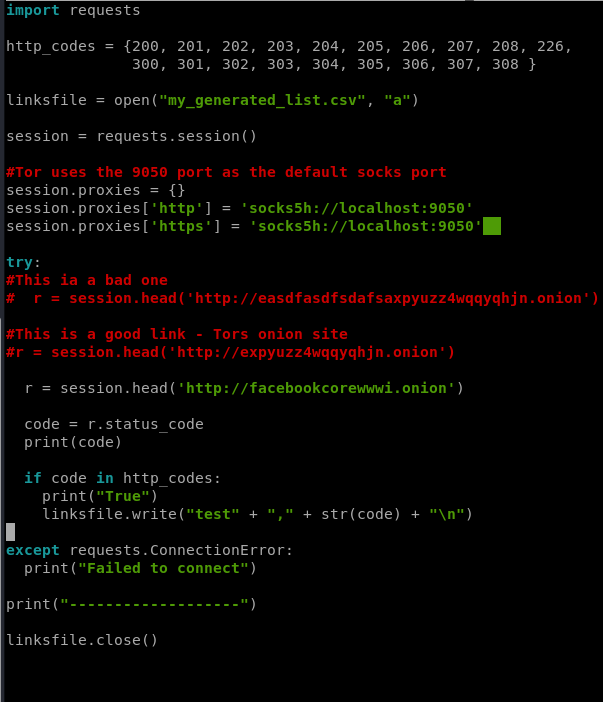
Yes, I realize I have some print statements that I don’t need in there right now but I’ll remove them later. And I should probably put some functions in here…but I’ll worry about that later. Or now…
Let’s start putting our random generator in…with a function!
Здесь вы можете заказать накрутку лайков и фолловеров для социальных сетях , таких как ВК, TikTok, Telegram и прочие.
Быстрая и безопасная раскрутка профиля гарантирована .
Купить лайки Ютуб
Доступные тарифы и качественное предоставление услуг.
Начните рост популярности уже сейчас !
На данном сайте вы можете приобрести онлайн телефонные номера разных операторов. Эти номера подходят для подтверждения профилей в разных сервисах и приложениях.
В ассортименте доступны как долговременные, так и одноразовые номера, которые можно использовать чтобы принять сообщений. Это удобное решение если вам не хочет использовать личный номер в интернете.
номер польши
Процесс покупки очень простой: определяетесь с подходящий номер, оплачиваете, и он становится готов к использованию. Оцените услугу уже сегодня!
This website specializes in desktop Video Surveillance Software, detailing free solutions for IP camera monitoring. It provides comparisons of various surveillance software and examines AI-powered security advancements, including cost-free object detection features. Reviews of both desktop and mobile applications focus on their usability and key attributes. The recommended software functions as a robust security tool, delivering precise detection capabilities. With IP camera recording and time-lapse support, it is a versatile choice for those seeking CCTV monitoring solutions.
На этом сайте вы можете приобрести онлайн мобильные номера различных операторов. Они могут использоваться для регистрации аккаунтов в различных сервисах и приложениях.
В каталоге представлены как постоянные, так и временные номера, что можно использовать чтобы принять SMS. Это удобное решение если вам не желает указывать личный номер в сети.
купить виртуальный номер
Процесс покупки очень удобный: определяетесь с необходимый номер, вносите оплату, и он будет доступен. Попробуйте сервис прямо сейчас!
На этом сайте АвиаЛавка (AviaLavka) вы можете забронировать дешевые авиабилеты по всему миру.
Мы подбираем лучшие цены от проверенных перевозчиков.
Удобный интерфейс поможет быстро найти подходящий рейс.
https://www.avialavka.ru
Гибкая система поиска помогает подобрать самые дешевые варианты перелетов.
Покупайте билеты онлайн без переплат.
АвиаЛавка — ваш удобный помощник в путешествиях!
На этом сайте вы у вас есть возможность купить лайки и фолловеров для Instagram. Это поможет повысить вашу популярность и заинтересовать больше людей. Мы предлагаем моментальное добавление и надежный сервис. Выбирайте удобный пакет и продвигайте свой аккаунт без лишних усилий.
Накрутка Инстаграм бесплатно быстро
Я боялся, что навсегда утратил свои биткоины, но специальный сервис помог мне их вернуть.
Изначально я сомневался, что что-то получится, но простой процесс оказался эффективным.
Используя уникальному подходу, платформа восстановила утерянные данные.
Всего за несколько шагов я удалось восстановить свои BTC.
Этот сервис оказался надежным, и я советую его тем, кто утратил доступ к своим криптоактивам.
http://mtw2014.tmweb.ru/forum/?PAGE_NAME=message&FID=1&TID=11953&TITLE_SEO=11953-programma-dlya-prosmotra-kamer-videonablyudeniya&MID=564385&result=reply#message564385
Этот сервис помогает накрутить просмотры и подписчиков во ВКонтакте. Вы можете заказать эффективное продвижение, которое поможет росту популярности вашей страницы или группы. Бот для накрутки просмотров в ВК видео Все подписчики реальные, а просмотры добавляются быстро. Доступные цены позволяют выбрать оптимальный вариант для разного бюджета. Оформление услуги занимает минимум времени, а результат виден уже в ближайшее время. Начните продвижение сегодня и сделайте свой профиль популярнее!
На этом ресурсе вы найдете клинику психологического здоровья, которая предоставляет психологические услуги для людей, страдающих от стресса и других ментальных расстройств. Мы предлагаем комплексное лечение для восстановления ментального здоровья. Наши специалисты готовы помочь вам решить проблемы и вернуться к гармонии. Опыт наших врачей подтверждена множеством положительных рекомендаций. Запишитесь с нами уже сегодня, чтобы начать путь к восстановлению.
http://helenfrankenthalerfoundation.com/__media__/js/netsoltrademark.php?d=empathycenter.ru%2Fpreparations%2Fk%2Fkorvalol%2F
Здесь вы найдете центр ментального здоровья, которая обеспечивает психологические услуги для людей, страдающих от тревоги и других психологических расстройств. Мы предлагаем комплексное лечение для восстановления психического здоровья. Наши опытные психологи готовы помочь вам справиться с проблемы и вернуться к сбалансированной жизни. Квалификация наших врачей подтверждена множеством положительных отзывов. Обратитесь с нами уже сегодня, чтобы начать путь к лучшей жизни.
http://jankelawgroup.com/__media__/js/netsoltrademark.php?d=empathycenter.ru%2Fpreparations%2Fz%2Fzopiklon%2F
Здесь вы найдете клинику ментального здоровья, которая предоставляет профессиональную помощь для людей, страдающих от тревоги и других психических расстройств. Эта эффективные методы для восстановления ментального здоровья. Наши специалисты готовы помочь вам решить трудности и вернуться к психологическому благополучию. Квалификация наших психологов подтверждена множеством положительных рекомендаций. Свяжитесь с нами уже сегодня, чтобы начать путь к лучшей жизни.
http://liafrazzini.com/__media__/js/netsoltrademark.php?d=empathycenter.ru%2Fpreparations%2Fo%2Folanzapin%2F
На данной платформе вы найдете центр ментального здоровья, которая предлагает профессиональную помощь для людей, страдающих от стресса и других психических расстройств. Эта комплексное лечение для восстановления психического здоровья. Наши опытные психологи готовы помочь вам решить трудности и вернуться к психологическому благополучию. Опыт наших специалистов подтверждена множеством положительных отзывов. Запишитесь с нами уже сегодня, чтобы начать путь к лучшей жизни.
http://littlebooproductionsclub.org/__media__/js/netsoltrademark.php?d=empathycenter.ru%2Fpreparations%2Fm%2Fmelatonin%2F
VectorJet is dedicated to coordinating exclusive aviation services, collective flights, and freight charters.
They deliver bespoke solutions for VIP jet journeys, air taxis, helicopter charters, and freight delivery, including priority and relief missions.
The company offers flexible travel options with individually tailored aircraft recommendations, 24/7 assistance, and help with unique requests, such as pet-friendly flights or remote destination access.
Complementary services cover aircraft leasing, brokerage, and private jet management.
VectorJet serves as an intermediary between travelers and third-party operators, ensuring luxury, convenience, and speed.
Their mission is to bring business jet travel effortless, safe, and personally designed for each client.
vector-jet.com
Предоставляем услуги проката автобусов и микроавтобусов с водителем корпоративным клиентам, бизнеса любого масштаба, а также для частных клиентов.
Пассажирские перевозки в Челябинске
Обеспечиваем приятную и спокойную транспортировку для групп людей, предлагая перевозки на свадебные мероприятия, корпоративные праздники, туристические поездки и любые события в регионе Челябинска.
Luxury timepieces have long been a gold standard in horology. Meticulously designed by world-class artisans, they combine heritage with innovation.
All elements demonstrate exceptional attention to detail, from precision-engineered calibers to high-end finishes.
Wearing a horological masterpiece is not just about telling time. It represents refined taste and exceptional durability.
Be it a minimalist aesthetic, Swiss watches provide unparalleled reliability that never goes out of style.
https://archboston.com/community/threads/watches-query.7227/
We offer a comprehensive collection of trusted pharmaceutical products for various needs.
Our online pharmacy provides quick and secure order processing to your location.
Each medication is sourced from licensed manufacturers so you get safety and quality.
Feel free to search through our catalog and place your order hassle-free.
Got any concerns? Pharmacy experts will guide you at any time.
Prioritize your well-being with our trusted online pharmacy!
https://www.linkcentre.com/review/shailoo.gov.kg/kg/vybory-oktyabr-2020_/plan-improving-health-elderly-population-disease-prevention/
Сертификация на территории РФ по-прежнему считается важным этапом легальной реализации товаров.
Система сертификации подтверждает соответствие техническим регламентам и правилам, что оберегает потребителей от небезопасной продукции.
оформление сертификатов
К тому же, официальное подтверждение качества облегчает взаимодействие с заказчиками и повышает возможности для бизнеса.
Без сертификации, возможны штрафы и барьеры при продаже товаров.
Вот почему, официальное подтверждение качества является не просто обязательным, а также залогом укрепления позиций бизнеса на отечественном рынке.
Обзор BlackSprut: ключевые особенности
Сервис BlackSprut вызывает обсуждения широкой аудитории. Но что это такое?
Этот проект предлагает интересные возможности для своих пользователей. Интерфейс платформы отличается простотой, что делает его доступной без сложного обучения.
Стоит учитывать, что данная система имеет свои особенности, которые делают его особенным на рынке.
Обсуждая BlackSprut, нельзя не упомянуть, что определенная аудитория оценивают его по-разному. Многие выделяют его удобство, а кто-то оценивают его неоднозначно.
Подводя итоги, BlackSprut остается темой дискуссий и вызывает заинтересованность широкой аудитории.
Ищете рабочее зеркало БлэкСпрут?
Если ищете актуальный домен BlackSprut, то вы по адресу.
bs2best at
Периодически ресурс меняет адрес, поэтому нужно знать новое зеркало.
Мы следим за актуальными доменами чтобы предоставить новым зеркалом.
Проверьте актуальную ссылку прямо сейчас!
Мы занимается помощью иностранных граждан в северной столице.
Оказываем содействие в подготовке документов, временной регистрации, и вопросах, для официального трудоустройства.
Наша команда консультируют по всем юридическим вопросам и дают советы правильный порядок действий.
Мы работаем как с временным пребыванием, и в вопросах натурализации.
С нами, процесс адаптации станет проще, упростить оформление документов и спокойно жить в северной столице.
Обращайтесь, чтобы узнать больше!
https://spb-migrant.ru/
Чем интересен BlackSprut?
Платформа BlackSprut привлекает интерес многих пользователей. В чем его особенности?
Этот проект предоставляет широкие опции для аудитории. Оформление сайта характеризуется удобством, что позволяет ей быть доступной даже для новичков.
Необходимо помнить, что BlackSprut имеет свои особенности, которые делают его особенным в определенной среде.
Говоря о BlackSprut, стоит отметить, что определенная аудитория выражают неоднозначные взгляды. Многие подчеркивают его функциональность, другие же рассматривают неоднозначно.
Подводя итоги, эта платформа продолжает быть объектом интереса и вызывает интерес широкой аудитории.
Обновленный сайт BlackSprut – ищите здесь
Если ищете актуальный домен BlackSprut, то вы по адресу.
bs2best at
Иногда ресурс меняет адрес, и тогда приходится искать новое зеркало.
Обновленный доступ всегда можно найти здесь.
Посмотрите актуальную версию сайта у нас!
Purchasing medications from e-pharmacies can be way easier than going to a physical pharmacy.
There’s no reason to deal with crowds or stress over limited availability.
E-pharmacies allow you to buy what you need with just a few clicks.
Many websites offer discounts in contrast to brick-and-mortar pharmacies.
http://www.feuchtwangen.info/viewtopic.php?f=2&t=160488
Additionally, it’s possible to compare various options easily.
Fast shipping adds to the ease.
What do you think about purchasing drugs from the internet?
Поклонники онлайн-казино всегда найдут актуальное зеркало онлайн-казино Champion чтобы без проблем запустить любимыми слотами.
На платформе можно найти разнообразные слоты, от олдскульных до новых, а также новейшие автоматы от мировых брендов.
Если главный ресурс не работает, рабочее зеркало Champion поможет моментально получить доступ и делать ставки без перебоев.
https://casino-champions-slots.ru
Весь функционал сохраняются, начиная от создания аккаунта, финансовые операции, и, конечно, бонусную систему.
Заходите через актуальную ссылку, и не терять доступ к казино Чемпион!
Что такое BlackSprut?
Платформа BlackSprut привлекает обсуждения многих пользователей. Но что это такое?
Данный ресурс предоставляет разнообразные возможности для своих пользователей. Интерфейс сайта выделяется функциональностью, что делает его интуитивно удобной даже для тех, кто впервые сталкивается с подобными сервисами.
Важно отметить, что этот ресурс обладает уникальными характеристиками, которые делают его особенным в своей нише.
При рассмотрении BlackSprut важно учитывать, что многие пользователи оценивают его по-разному. Некоторые отмечают его функциональность, другие же рассматривают с осторожностью.
Подводя итоги, данный сервис остается темой дискуссий и привлекает интерес разных слоев интернет-сообщества.
Ищете актуальное зеркало БлэкСпрут?
Хотите узнать актуальное зеркало на БлэкСпрут? Это можно сделать здесь.
https://bs2best
Сайт может меняться, поэтому важно иметь актуальный линк.
Мы мониторим за изменениями и готовы поделиться актуальным зеркалом.
Проверьте рабочую версию сайта прямо сейчас!
This portal features a wide selection of slot games, ideal for both beginners and experienced users.
Here, you can find traditional machines, feature-rich games, and huge-win machines with high-quality visuals and dynamic music.
No matter if you’re a fan of minimal mechanics or seek bonus-rich rounds, this site has a perfect match.
https://paradigma64.ru/wp-content/pgs/vina_shardone_na_chto_sleduet_obratity_vnimanie_pri_vybore.html
All games can be accessed around the clock, right in your browser, and fully optimized for both PC and mobile.
Apart from the machines, the site includes slot guides, bonuses, and user ratings to help you choose.
Sign up, start playing, and enjoy the excitement of spinning!
Taking one’s own life is a serious phenomenon that impacts millions of people around the globe.
It is often associated with psychological struggles, such as depression, stress, or addiction problems.
People who contemplate suicide may feel isolated and believe there’s no hope left.
how-to-kill-yourself.com
It is important to talk openly about this matter and support those in need.
Mental health care can reduce the risk, and reaching out is a necessary first step.
If you or someone you know is thinking about suicide, don’t hesitate to get support.
You are not forgotten, and support exists.
На этом сайте вы можете испытать обширной коллекцией игровых автоматов.
Слоты обладают живой визуализацией и увлекательным игровым процессом.
Каждая игра даёт уникальные бонусные раунды, увеличивающие шансы на выигрыш.
1xbet казино официальный сайт
Игра в слоты подходит любителей азартных игр всех мастей.
Можно опробовать игру без ставки, после чего начать играть на реальные деньги.
Испытайте удачу и насладитесь неповторимой атмосферой игровых автоматов.
На этом сайте вы можете наслаждаться широким ассортиментом игровых слотов.
Игровые автоматы характеризуются яркой графикой и интерактивным игровым процессом.
Каждый игровой автомат предоставляет особые бонусные возможности, увеличивающие шансы на выигрыш.
1win
Игра в игровые автоматы предназначена любителей азартных игр всех мастей.
Можно опробовать игру без ставки, а затем перейти к игре на реальные деньги.
Попробуйте свои силы и окунитесь в захватывающий мир слотов.
На нашей платформе можно найти популярные слот-автоматы.
На сайте представлены лучшую коллекцию слотов от ведущих провайдеров.
Любой автомат обладает высоким качеством, призовыми раундами и максимальной волатильностью.
http://mterentiev.ru/bitrix/redirect.php?event1=&event2=&event3=&goto=https://casinoreg.net/
Пользователи могут играть в демо-режиме или играть на деньги.
Навигация по сайту интуитивно понятны, что облегчает поиск игр.
Если вас интересуют слоты, здесь вы точно найдете что-то по душе.
Начинайте играть уже сегодня — возможно, именно сегодня вам повезёт!
Здесь вы обнаружите интересные игровые слоты на платформе Champion.
Выбор игр представляет классические автоматы и актуальные новинки с качественной анимацией и разнообразными функциями.
Всякий автомат оптимизирован для максимального удовольствия как на ПК, так и на смартфонах.
Независимо от опыта, здесь вы сможете выбрать что-то по вкусу.
champion casino зеркало
Автоматы запускаются в любое время и не требуют скачивания.
Дополнительно сайт предлагает программы лояльности и рекомендации, чтобы сделать игру ещё интереснее.
Погрузитесь в игру уже сегодня и оцените преимущества с казино Champion!
На данной платформе можно найти слоты платформы Vavada.
Каждый пользователь может подобрать слот на свой вкус — от традиционных аппаратов до видеослотов разработок с яркой графикой.
Казино Vavada предоставляет широкий выбор популярных игр, включая игры с джекпотом.
Любой автомат запускается в любое время и оптимизирован как для настольных устройств, так и для планшетов.
вавада зеркало
Каждый геймер ощутит азартом, не выходя из любимого кресла.
Интерфейс сайта удобна, что даёт возможность моментально приступить к игре.
Начните прямо сейчас, чтобы открыть для себя любимые слоты!
Площадка BlackSprut — это довольно популярная систем в darknet-среде, предоставляющая разнообразные сервисы в рамках сообщества.
Здесь предусмотрена понятная система, а интерфейс понятен даже новичкам.
Пользователи отмечают стабильность работы и постоянные обновления.
bs2best.markets
Площадка разработана на комфорт и минимум лишней информации при использовании.
Тех, кто изучает инфраструктуру darknet, этот проект станет удобной точкой старта.
Перед началом не лишним будет прочитать информацию о работе Tor.
Thanks on your marvelous posting! I certainly enjoyed reading it, you might be a great author.I will remember to bookmark your blog and will eventually come back later in life. I want to encourage yourself to continue your great job, have a nice day!
Новый летний период обещает быть ярким и оригинальным в плане моды.
В тренде будут натуральные ткани и игра фактур.
Цветовая палитра включают в себя неоновые оттенки, выделяющие образ.
Особое внимание дизайнеры уделяют принтам, среди которых популярны объёмные украшения.
https://km-moda.ru/style/525-parajumpers-istoriya-stil-i-assortiment/
Набирают популярность элементы 90-х, интерпретированные по-новому.
На подиумах уже можно увидеть захватывающие образы, которые поражают.
Следите за обновлениями, чтобы вписаться в тренды.
This website, you can access lots of casino slots from top providers.
Visitors can try out classic slots as well as feature-packed games with stunning graphics and interactive gameplay.
Even if you’re new or an experienced player, there’s a game that fits your style.
casino games
The games are available 24/7 and designed for laptops and mobile devices alike.
You don’t need to install anything, so you can jump into the action right away.
Site navigation is easy to use, making it quick to explore new games.
Register now, and enjoy the world of online slots!
Here, you can access a wide selection of slot machines from leading developers.
Players can experience retro-style games as well as new-generation slots with vivid animation and exciting features.
Whether you’re a beginner or a casino enthusiast, there’s something for everyone.
slot casino
All slot machines are available anytime and optimized for laptops and smartphones alike.
No download is required, so you can jump into the action right away.
Platform layout is easy to use, making it convenient to browse the collection.
Join the fun, and enjoy the world of online slots!
Our e-pharmacy features a wide range of pharmaceuticals with competitive pricing.
Customers can discover all types of drugs for all health requirements.
We work hard to offer safe and effective medications while saving you money.
Fast and reliable shipping guarantees that your purchase is delivered promptly.
Experience the convenience of shopping online on our platform.
generic ed drugs
On this site showcases disc player alarm devices crafted by trusted manufacturers.
Here you’ll discover premium CD devices with FM/AM reception and two alarm settings.
Most units come with auxiliary inputs, device charging, and memory backup.
The selection covers budget-friendly options to elite choices.
cd player alarm clock
Every model provide nap modes, sleep timers, and LED screens.
Shop the collection through Amazon and no extra cost.
Discover your ultimate wake-up solution for office convenience.
This service features buggy hire throughout Crete.
Anyone can easily arrange a vehicle for exploration.
When you’re looking to discover natural spots, a buggy is the perfect way to do it.
https://linktr.ee/buggycrete
The fleet are well-maintained and offered in custom schedules.
Booking through this site is user-friendly and comes with no hidden fees.
Start your journey and enjoy Crete like never before.
Here, you can access lots of slot machines from top providers.
Players can enjoy retro-style games as well as new-generation slots with vivid animation and bonus rounds.
Even if you’re new or an experienced player, there’s something for everyone.
money casino
All slot machines are instantly accessible 24/7 and compatible with PCs and mobile devices alike.
No download is required, so you can jump into the action right away.
The interface is intuitive, making it simple to browse the collection.
Join the fun, and dive into the world of online slots!
Предстоящее лето обещает быть стильным и экспериментальным в плане моды.
В тренде будут многослойность и игра фактур.
Модные цвета включают в себя неоновые оттенки, подчеркивающие индивидуальность.
Особое внимание дизайнеры уделяют тканям, среди которых популярны винтажные очки.
https://orlandomagicclub.com/read-blog/6136
Возвращаются в моду элементы ретро-стиля, в свежем прочтении.
В новых коллекциях уже можно увидеть трендовые образы, которые впечатляют.
Будьте в курсе, чтобы вписаться в тренды.
Оформление страховки перед поездкой за рубеж — это важный шаг для защиты здоровья туриста.
Страховка покрывает медицинские услуги в случае несчастного случая за границей.
К тому же, страховка может предусматривать оплату на репатриацию.
carbox30.ru
Многие страны настаивают на наличие страховки для посещения.
Без наличия документа медицинские расходы могут привести к большим затратам.
Оформление полиса заранее
Classic wristwatches will forever stay in style.
They represent craftsmanship and showcase a sense of artistry that digital devices simply don’t replicate.
Each piece is powered by tiny components, making it both useful and inspiring.
Collectors appreciate the intricate construction.
https://sites.google.com/view/watchcrazy/audemars-piguet
Wearing a mechanical watch is not just about utility, but about making a statement.
Their shapes are classic, often passed from generation to generation.
Ultimately, mechanical watches will stand the test of time.
The site allows you to find specialists for temporary hazardous projects.
Visitors are able to easily arrange help for unique operations.
All contractors are trained in handling sensitive activities.
hitman-assassin-killer.com
Our platform ensures safe connections between users and freelancers.
For those needing fast support, our service is ready to help.
List your task and match with a professional in minutes!
Questa pagina permette l’assunzione di persone per lavori pericolosi.
Gli interessati possono ingaggiare esperti affidabili per lavori una tantum.
Gli operatori proposti vengono verificati con severi controlli.
assumi un sicario
Con il nostro aiuto è possibile ottenere informazioni dettagliate prima della scelta.
La qualità rimane un nostro impegno.
Sfogliate i profili oggi stesso per trovare il supporto necessario!
В этом разделе вы можете получить актуальное зеркало 1хбет без блокировок.
Постоянно обновляем доступы, чтобы обеспечить беспрепятственный доступ к платформе.
Открывая резервную копию, вы сможете пользоваться всеми функциями без задержек.
1xbet-official.live
Наш сайт поможет вам быстро найти актуальный адрес 1xBet.
Мы заботимся, чтобы все клиенты был в состоянии получить полный доступ.
Следите за обновлениями, чтобы всегда быть онлайн с 1хБет!
Наша платформа — подтверждённый онлайн-магазин Bottega Венета с отгрузкой по стране.
В нашем магазине вы можете купить эксклюзивные вещи Bottega Veneta официально.
Каждый заказ идут с официальной гарантией от производителя.
bottega-official.ru
Отправка осуществляется без задержек в любой регион России.
Бутик онлайн предлагает удобную оплату и простую процедуру возврата.
Выбирайте официальном сайте Bottega Veneta, чтобы быть уверенным в качестве!
在此页面,您可以聘请专门从事一次性的危险工作的专业人士。
我们汇集大量经验丰富的从业人员供您选择。
无论是何种高风险任务,您都可以方便找到合适的人选。
chinese-hitman-assassin.com
所有任务完成者均经过审核,维护您的机密信息。
服务中心注重专业性,让您的危险事项更加无忧。
如果您需要服务详情,请随时咨询!
Seeking to hire reliable contractors available for short-term hazardous projects.
Need a freelancer to complete a perilous task? Connect with certified experts via this site to manage critical dangerous operations.
rent a hitman
This website connects businesses to skilled workers prepared to take on hazardous short-term gigs.
Recruit verified freelancers for risky tasks safely. Ideal when you need emergency scenarios requiring safety-focused skills.
People consider taking their own life due to many factors, frequently stemming from intense psychological suffering.
A sense of despair may consume someone’s will to live. Often, loneliness is a major factor in pushing someone toward such thoughts.
Psychological disorders impair decision-making, making it hard for individuals to find other solutions beyond their current state.
how to kill yourself
External pressures might further drive an individual to consider drastic measures.
Lack of access to help can make them feel stuck. Understand getting help is crucial.
欢迎光临,这是一个成人网站。
进入前请确认您已年满成年年龄,并同意接受相关条款。
本网站包含限制级信息,请谨慎浏览。 色情网站。
若不符合年龄要求,请立即退出页面。
我们致力于提供健康安全的成人服务。
Here you can discover valuable information about ways of becoming a IT infiltrator.
Data is shared in a easily digestible manner.
You may acquire diverse strategies for penetrating networks.
Plus, there are hands-on demonstrations that illustrate how to apply these competencies.
how to become a hacker
All information is periodically modified to match the newest developments in data safeguarding.
Special attention is centered around functional usage of the learned skills.
Be aware that any undertaking should be implemented properly and with moral considerations only.
Here can be found unique promo codes for 1x betting.
These bonuses provide an opportunity to obtain bonus rewards when participating on the website.
Every listed promotional codes are always up-to-date to ensure their validity.
With these codes you can significantly increase your gaming experience on 1xBet.
https://paranormalmusings.com/wp-content/pgs/dghinsovye_kurtki_kak_ih_pravilyno_ispolyzovaty_i_chto_budet_modno.html
Moreover, step-by-step directions on how to implement promo deals are available for convenience.
Note that specific offers may have specific terms, so look into conditions before using.
The site offers a wide range of pharmaceuticals for easy access.
Customers are able to easily get health products from your device.
Our inventory includes popular drugs and more specific prescriptions.
The full range is supplied through reliable providers.
cenforce soft 100
We prioritize quality and care, with private checkout and timely service.
Whether you’re managing a chronic condition, you’ll find safe products here.
Start your order today and get reliable healthcare delivery.
1XBet is a premier gambling provider.
Featuring a broad variety of events, 1xBet serves millions globally.
The One X Bet mobile app crafted for both Android as well as iOS players.
https://bpcnitrkl.in/art/samyy_luchshiy_menyshiy_brat.html
You can download the application from the platform’s page as well as Google’s store for Android.
iPhone customers, the application can be downloaded from the official iOS store with ease.
1XBet Promotional Code – Special Bonus maximum of $130
Enter the 1XBet promotional code: Code 1XBRO200 during sign-up on the app to unlock exclusive rewards provided by 1XBet and get $130 up to 100%, for placing bets along with a €1950 including one hundred fifty free spins. Start the app followed by proceeding by completing the registration procedure.
This One X Bet promo code: 1xbro200 provides an amazing welcome bonus for new users — full one hundred percent up to €130 during sign-up. Bonus codes serve as the key for accessing extra benefits, plus One X Bet’s promo codes are the same. By using such a code, bettors have the chance of various offers in various phases of their betting experience. Although you’re not eligible to the starter reward, One X Bet India makes sure its regular customers are rewarded through regular bonuses. Visit the Offers page via their platform frequently to stay updated on the latest offers meant for existing players.
1xbet promo code for registration
Which 1XBet promotional code is currently active at this moment?
The promotional code relevant to 1xBet stands as 1xbro200, enabling novice players signing up with the gambling provider to unlock an offer worth $130. For gaining exclusive bonuses related to games and wagering, kindly enter our bonus code related to 1XBET during the sign-up process. To take advantage from this deal, potential customers need to type the promotional code 1xbet at the time of registering procedure to receive double their deposit amount for their first payment.
Здесь вы можете найти последние коды для Melbet.
Примените коды при регистрации на платформе для получения полный бонус на первый депозит.
Также, доступны коды для текущих акций игроков со стажем.
melbet промокод без депозита
Следите за обновлениями в разделе промокодов, не пропустив выгодные предложения для Мелбет.
Любой код проверяется на работоспособность, поэтому вы можете быть уверены при использовании.
В данной платформе доступны живые видеочаты.
Вы хотите увлекательные диалоги переговоры, на платформе представлены что-то подходящее.
Функция видеочата разработана для взаимодействия глобально.
видео чат порно пары
Благодаря HD-качеству и превосходным звуком, вся беседа кажется естественным.
Подключиться в общий чат инициировать приватный разговор, исходя из ваших предпочтений.
Все, что требуется — стабильное интернет-соединение и любое поддерживаемое устройство, и можно общаться.
On this platform, you can access a wide selection of online slots from leading developers.
Players can experience traditional machines as well as feature-packed games with vivid animation and exciting features.
Whether you’re a beginner or a casino enthusiast, there’s something for everyone.
slots
The games are ready to play 24/7 and optimized for desktop computers and smartphones alike.
You don’t need to install anything, so you can get started without hassle.
The interface is intuitive, making it convenient to explore new games.
Register now, and dive into the thrill of casino games!
Handcrafted mechanical watches stand as the epitome of timeless elegance.
In a world full of smart gadgets, they consistently hold their sophistication.
Designed with precision and mastery, these timepieces reflect true horological mastery.
Unlike fleeting trends, mechanical watches do not go out of fashion.
https://www.vevioz.com/read-blog/171062
They stand for heritage, tradition, and enduring quality.
Whether worn daily or saved for special occasions, they always remain in style.
Within this platform, explore an extensive selection virtual gambling platforms.
Searching for classic games or modern slots, there’s something to suit all preferences.
The listed platforms are verified to ensure security, allowing users to gamble securely.
vavada
Additionally, this resource unique promotions and deals to welcome beginners as well as regulars.
With easy navigation, finding your favorite casino takes just moments, saving you time.
Stay updated on recent updates with frequent visits, because updated platforms appear consistently.
这个网站 提供 多样的 成人内容,满足 不同用户 的 兴趣。
无论您喜欢 哪一类 的 影片,这里都 应有尽有。
所有 材料 都经过 精心筛选,确保 高质量 的 观看体验。
私人视频
我们支持 各种终端 访问,包括 手机,随时随地 畅享内容。
加入我们,探索 无限精彩 的 两性空间。
На этом сайте эротические материалы.
Контент подходит для зрелых пользователей.
У нас собраны видео и изображения на любой вкус.
Платформа предлагает лучшие материалы в сети.
порно онлайн зрелые женщины
Вход разрешен только после проверки.
Наслаждайтесь простым поиском.
Модные образы для торжеств нынешнего года отличаются разнообразием.
В тренде стразы и пайетки из полупрозрачных тканей.
Блестящие ткани создают эффект жидкого металла.
Греческий стиль с драпировкой возвращаются в моду.
Разрезы на юбках подчеркивают элегантность.
Ищите вдохновение в новых коллекциях — детали и фактуры оставят в памяти гостей!
https://songpuai.go.th/forum/suggestion-box/485420-r-nd-vi-sv-d-bni-br-zi-e-g-g-d-vibr-i
Модные образы для торжеств этого сезона отличаются разнообразием.
В тренде стразы и пайетки из полупрозрачных тканей.
Металлические оттенки делают платье запоминающимся.
Греческий стиль с драпировкой определяют современные тренды.
Минималистичные силуэты создают баланс между строгостью и игрой.
Ищите вдохновение в новых коллекциях — стиль и качество превратят вас в звезду вечера!
http://www.victoriarabien.ugu.pl/forum/viewtopic.php?f=2&t=138997
The Piguet 15300ST combines meticulous craftsmanship with elegant design. Its 39mm case guarantees a modern fit, achieving harmony between prominence and wearability. The iconic octagonal bezel, secured by eight hexagonal screws, epitomizes the brand’s innovative approach to luxury sports watches.
Piguet 15300ST
Boasting a white gold baton hour-marker dial, this model includes a 60-hour power reserve via the selfwinding mechanism. The intricate guilloché motif adds depth and character, while the streamlined construction ensures discreet luxury.
The AP Royal Oak 15400ST is a stainless steel timepiece introduced in 2012 of the legendary Royal Oak collection.
Its 41mm stainless steel case boasts an octagonal bezel secured with eight visible screws, a hallmark of the Royal Oak’s bold aesthetic.
Powered by the automatic Cal. 3120 movement, guarantees seamless functionality with a date display at 3 o’clock.
AP Royal Oak 15400ST
The dial showcases a black Grande Tapisserie pattern highlighted by luminous appliqués for clear visibility.
A seamless steel link bracelet offers a secure, ergonomic fit, finished with an AP folding clasp.
Celebrated for its high recognition value, this model remains a top choice among luxury watch enthusiasts.
Thanks for all your efforts that you have put in this. very interesting info .
Здесь можно получить сервис “Глаз Бога”, позволяющий найти сведения о человеке по публичным данным.
Сервис работает по ФИО, используя актуальные базы в сети. Через бота доступны бесплатный поиск и полный отчет по запросу.
Сервис обновлен на август 2024 и охватывает мультимедийные данные. Бот сможет узнать данные по госреестрам и отобразит информацию мгновенно.
https://glazboga.net/
Это сервис — идеальное решение при поиске граждан онлайн.
Лицензирование и сертификация — обязательное условие ведения бизнеса в России, гарантирующий защиту от непрофессионалов.
Декларирование продукции требуется для подтверждения соответствия стандартам.
Для торговли, логистики, финансов необходимо получение лицензий.
https://ok.ru/group/70000034956977/topic/158831459350705
Игнорирование требований ведут к приостановке деятельности.
Дополнительные лицензии помогает повысить доверие бизнеса.
Соблюдение норм — залог успешного развития компании.
Здесь вы найдете сервис “Глаз Бога”, что найти сведения о гражданине через открытые базы.
Инструмент активно ищет по номеру телефона, используя публичные материалы в Рунете. Через бота доступны пять пробивов и глубокий сбор по фото.
Инструмент обновлен на 2025 год и охватывает аудио-материалы. Бот поможет найти профили по госреестрам и покажет результаты в режиме реального времени.
https://glazboga.net/
Данный инструмент — идеальное решение при поиске граждан онлайн.
На данном сайте можно получить мессенджер-бот “Глаз Бога”, который найти данные о человеке по публичным данным.
Сервис работает по ФИО, анализируя публичные материалы в сети. Благодаря ему можно получить бесплатный поиск и детальный анализ по фото.
Платформа обновлен на август 2024 и включает фото и видео. Бот сможет узнать данные по госреестрам и покажет информацию за секунды.
https://glazboga.net/
Такой бот — выбор для проверки граждан удаленно.
¿Necesitas cupones exclusivos de 1xBet? Aquí podrás obtener las mejores ofertas en apuestas deportivas .
El promocódigo 1x_12121 garantiza a un bono de 6500 rublos para nuevos usuarios.
Para completar, activa 1XRUN200 y obtén un bono máximo de 32500 rublos .
https://anotepad.com/notes/aeax4emi
Mantente atento las ofertas diarias para acumular recompensas adicionales .
Las ofertas disponibles están actualizados para hoy .
¡Aprovecha y maximiza tus apuestas con 1xBet !
I’ve been browsing on-line more than three hours lately, but I by no means found any fascinating article like yours. It is beautiful price enough for me. Personally, if all website owners and bloggers made excellent content material as you probably did, the web might be a lot more useful than ever before.
Здесь вы можете получить доступ к актуальными новостями страны и зарубежья .
Информация поступает ежеминутно .
Освещаются фоторепортажи с эпицентров происшествий .
Мнения журналистов помогут глубже изучить тему .
Контент предоставляется без регистрации .
https://chenews.ru
Discover detailed information about the Audemars Piguet Royal Oak Offshore 15710ST here , including pricing insights ranging from $34,566 to $36,200 for stainless steel models.
The 42mm timepiece boasts a robust design with selfwinding caliber and water resistance , crafted in rose gold .
https://ap15710st.superpodium.com
Compare secondary market data , where limited editions reach up to $750,000 , alongside rare references from the 1970s.
Request real-time updates on availability, specifications, and resale performance , with trend reports for informed decisions.
Looking for exclusive 1xBet promo codes? This site offers verified bonus codes like 1XRUN200 for registrations in 2025. Claim €1500 + 150 FS as a welcome bonus.
Activate trusted promo codes during registration to boost your rewards. Benefit from no-deposit bonuses and exclusive deals tailored for sports betting.
Find daily updated codes for 1xBet Kazakhstan with guaranteed payouts.
Every promotional code is tested for validity.
Grab limited-time offers like 1x_12121 to double your funds.
Active for first-time deposits only.
https://gravatar.com/codigo1xbet2
Enjoy seamless rewards with easy redemption.
Founded in 2001 , Richard Mille redefined luxury watchmaking with cutting-edge innovation . The brand’s signature creations combine aerospace-grade ceramics and sapphire to enhance performance.
Mirroring the precision of racing cars , each watch prioritizes functionality , optimizing resistance. Collections like the RM 001 Tourbillon set new benchmarks since their debut.
Richard Mille’s experimental research in mechanical engineering yield skeletonized movements crafted for elite athletes.
Certified Richard Mille RM 1103 models
Rooted in innovation, the brand pushes boundaries through limited editions for collectors .
Since its inception, Richard Mille epitomizes luxury fused with technology , captivating discerning enthusiasts .
Launched in 1972, the Royal Oak revolutionized luxury watchmaking with its signature angular case and stainless steel craftsmanship .
Ranging from limited-edition sand gold to diamond-set variants, the collection combines avant-garde design with horological mastery.
Starting at $20,000 to over $400,000, these timepieces attract both luxury enthusiasts and aficionados seeking wearable heritage.
Verified Piguet Oak 26240 photos
The Royal Oak Offshore push boundaries with robust case constructions, showcasing Audemars Piguet’s technical prowess .
Thanks to ultra-thin calibers like the 2385, each watch epitomizes the brand’s commitment to excellence .
Explore certified pre-owned editions and historical insights to elevate your collection with this timeless icon .
Die Royal Oak 16202ST kombiniert ein 39-mm-Edelstahlgehäuse mit einem extraflachen Gehäuse von nur 8,1 mm Dicke.
Ihr Herzstück bildet das neue Kaliber 7121 mit erweitertem Energievorrat.
Der smaragdene Farbverlauf des Zifferblatts wird durch das feine Guillochierungen und die kratzfeste Saphirscheibe mit Antireflexbeschichtung betont.
Neben klassischer Zeitmessung bietet die Uhr ein Datumsfenster bei 3 Uhr.
Piguet Royal Oak 14790 armbanduhr
Die 50-Meter-Wasserdichte macht sie alltagstauglich.
Das integrierte Edelstahlarmband mit verstellbarem Dornschließe und die achtseitige Rahmenform zitieren das ikonische Royal-Oak-Erbe aus den 1970er Jahren.
Als Teil der „Jumbo“-Kollektion verkörpert die 16202ST meisterliche Uhrmacherkunst mit einem Wertanlage für Sammler.
Стальные резервуары используются для хранения дизельного топлива и соответствуют стандартам давления до 0,04 МПа.
Горизонтальные емкости изготавливают из нержавеющих сплавов с усиленной сваркой.
Идеальны для АЗС: хранят бензин, керосин, мазут или биодизель.
Резервуар РГСп 150 м3
Двустенные резервуары обеспечивают экологическую безопасность, а подземные модификации подходят для разных условий.
Заводы предлагают индивидуальные проекты объемом до 100 м³ с технической поддержкой.
High-end timepieces stay in demand for many compelling factors.
Their handmade precision and heritage place them above the rest.
They symbolize status and success while merging practicality and style.
Unlike digital gadgets, they endure through generations due to artisanal creation.
https://graph.org/Audemars-Piguet-Royal-Oak-15450ST-Ein-Meisterwerk-der-Uhrmacherkunst-06-14
Collectors and enthusiasts respect the legacy they carry that modern tech cannot imitate.
For many, having them signifies taste that defies time itself.
Наш ресурс публикует важные инфосообщения со всего мира.
Здесь можно найти факты и мнения, культуре и многом другом.
Контент пополняется регулярно, что позволяет следить за происходящим.
Простой интерфейс делает использование комфортным.
https://irkpress.ru
Каждая статья проходят проверку.
Редакция придерживается честной подачи.
Следите за обновлениями, чтобы быть всегда информированными.
Коллекция Nautilus, созданная Жеральдом Гентой, сочетает элегантность и прекрасное ремесленничество. Модель Nautilus 5711 с автоматическим калибром 324 SC имеет 45-часовой запас хода и корпус из нержавеющей стали.
Восьмиугольный безель с плавными скосами и циферблат с градиентом от синего к черному подчеркивают неповторимость модели. Браслет с интегрированными звеньями обеспечивает комфорт даже при повседневном использовании.
Часы оснащены функцией даты в позиции 3 часа и антибликовым покрытием.
Для сложных модификаций доступны секундомер, вечный календарь и функция Travel Time.
Купить часы Патек Филип Наутилус оригинал
Например, модель 5712/1R-001 из розового золота с калибром повышенной сложности и запасом хода на двое суток.
Nautilus остается символом статуса, объединяя современные технологии и классические принципы.
Wagering has become an exciting way to add excitement to your entertainment. Engaging with soccer, the service offers great opportunities for each user.
Through real-time gambling to scheduled events, access a wide variety of betting markets tailored to your preferences. The easy-to-use design ensures that engaging in betting is both effortless and secure.
https://alhudapk.com/dua/pages/?arada_bet___top_sports_betting_site_in_ethiopia.html
Get started to enjoy the top-tier gaming available online.
Размещение систем видеонаблюдения обеспечит контроль вашего объекта в режиме 24/7.
Современные технологии позволяют организовать высокое качество изображения даже в темное время суток.
Наша компания предоставляет широкий выбор систем, адаптированных для бизнеса и частных объектов.
videonablyudeniemoskva.ru
Грамотная настройка и сервисное обслуживание делают процесс максимально удобным для каждого клиента.
Обратитесь сегодня, и узнать о лучшее решение для установки видеонаблюдения.
Прямо здесь вы найдете сервис “Глаз Бога”, позволяющий найти сведения о гражданине через открытые базы.
Сервис активно ищет по ФИО, анализируя доступные данные в Рунете. Благодаря ему можно получить бесплатный поиск и глубокий сбор по фото.
Сервис обновлен на август 2024 и поддерживает мультимедийные данные. Бот гарантирует узнать данные по госреестрам и отобразит результаты мгновенно.
глаз бога телеграмм официальный
Данный бот — помощник для проверки граждан онлайн.
Vous cherchez des jeux en ligne ? Notre plateforme propose des centaines de titres pour tous les goûts .
Des jeux de cartes aux défis multijoueurs , plongez des univers captivants directement depuis votre navigateur.
Testez les nouveautés comme le Sudoku ou des aventures dynamiques en solo .
Pour les compétiteurs , des jeux de football en mode battle royale vous attendent.
https://qualiteonline.com/roulette.html
Profitez d’expériences premium et rejoignez une communauté active .
Quel que soit l’action, cette bibliothèque virtuelle s’impose comme votre destination préférée .
На данном сайте можно получить Telegram-бот “Глаз Бога”, позволяющий найти сведения о человеке из открытых источников.
Бот работает по ФИО, используя публичные материалы в Рунете. Через бота доступны 5 бесплатных проверок и глубокий сбор по фото.
Инструмент проверен согласно последним данным и поддерживает фото и видео. Бот гарантирует узнать данные в открытых базах и предоставит информацию в режиме реального времени.
глаз бога телефон
Такой сервис — выбор при поиске людей удаленно.
demais este conteúdo. Gostei muito. Aproveitem e vejam este site. informações, novidades e muito mais. Não deixem de acessar para descobrir mais. Obrigado a todos e até a próxima. 🙂
Нужно собрать информацию о пользователе? Наш сервис предоставит полный профиль мгновенно.
Используйте продвинутые инструменты для анализа цифровых следов в соцсетях .
Узнайте контактные данные или активность через автоматизированный скан с верификацией результатов.
глаз бога пробить номер
Система функционирует в рамках закона , обрабатывая открытые данные .
Закажите расширенный отчет с геолокационными метками и графиками активности .
Попробуйте проверенному решению для исследований — результаты вас удивят !
fantástico este conteúdo. Gostei muito. Aproveitem e vejam este conteúdo. informações, novidades e muito mais. Não deixem de acessar para se informar mais. Obrigado a todos e até mais. 🙂
Наш сервис способен найти информацию по заданному профилю.
Укажите никнейм в соцсетях, чтобы получить сведения .
Система анализирует открытые источники и цифровые следы.
найти через глаз бога
Результаты формируются мгновенно с фильтрацией мусора.
Идеально подходит для анализа профилей перед сотрудничеством .
Анонимность и точность данных — наш приоритет .
Этот бот поможет получить данные по заданному профилю.
Достаточно ввести имя, фамилию , чтобы получить сведения .
Бот сканирует открытые источники и цифровые следы.
бот глаз бога информация
Результаты формируются в реальном времени с проверкой достоверности .
Оптимален для проверки партнёров перед важными решениями.
Конфиденциальность и актуальность информации — наш приоритет .
Нужно найти данные о пользователе? Этот бот поможет полный профиль мгновенно.
Используйте продвинутые инструменты для анализа цифровых следов в соцсетях .
Выясните контактные данные или активность через систему мониторинга с верификацией результатов.
глаз бога телеграмм сайт
Система функционирует в рамках закона , используя только открытые данные .
Получите детализированную выжимку с геолокационными метками и списком связей.
Попробуйте надежному помощнику для digital-расследований — точность гарантирована!
На данном сайте можно найти данные по запросу, от кратких контактов до полные анкеты.
Реестры включают граждан разного возраста, статусов.
Данные агрегируются на основе публичных данных, что гарантирует точность.
Обнаружение осуществляется по фамилии, что обеспечивает процесс удобным.
глаз бога узнать номер
Также предоставляются адреса и другая важные сведения.
Работа с информацией обрабатываются в соответствии с норм права, предотвращая несанкционированного доступа.
Обратитесь к данному ресурсу, для поиска нужные сведения в кратчайшие сроки.
На данном сайте доступна информация по запросу, включая исчерпывающие сведения.
Архивы охватывают граждан любой возрастной категории, статусов.
Сведения формируются на основе публичных данных, подтверждая точность.
Нахождение осуществляется по контактным данным, что делает использование эффективным.
глаз бога фото телеграм
Помимо этого доступны места работы плюс важные сведения.
Все запросы выполняются с соблюдением законодательства, что исключает утечек.
Обратитесь к предложенной системе, в целях получения искомые данные без лишних усилий.
I am impressed with this site, rattling I am a fan.
Хотите найти информацию о человеке ? Этот бот поможет полный профиль в режиме реального времени .
Используйте уникальные алгоритмы для анализа публичных записей в открытых источниках.
Узнайте контактные данные или интересы через автоматизированный скан с верификацией результатов.
глаз бога телеграмм официальный бот
Система функционирует с соблюдением GDPR, обрабатывая общедоступную информацию.
Получите детализированную выжимку с историей аккаунтов и графиками активности .
Доверьтесь надежному помощнику для digital-расследований — точность гарантирована!
Подбирая семейного медика важно учитывать на квалификацию, стиль общения и удобные часы приема.
Убедитесь, что медицинский центр расположена рядом и предоставляет полный спектр услуг .
Спросите, принимает ли врач с вашей полисом, и есть ли возможность записи онлайн .
https://forum.eass-germany.de/viewtopic.php?t=108
Оценивайте отзывы пациентов , чтобы оценить отношение к клиентам.
Не забудьте наличие профильного образования, аккредитацию клиники для уверенности в качестве лечения.
Выбирайте — тот, где примут во внимание ваши особенности здоровья, а общение с персоналом будет комфортным .
В этом ресурсе предоставляется информация о любом человеке, от кратких контактов до исчерпывающие сведения.
Реестры охватывают людей разного возраста, статусов.
Сведения формируются из открытых источников, подтверждая точность.
Поиск осуществляется по контактным данным, что делает процесс эффективным.
глаз бога тг
Дополнительно можно получить адреса а также актуальные данные.
Обработка данных выполняются в соответствии с законодательства, обеспечивая защиту несанкционированного доступа.
Обратитесь к предложенной системе, для поиска нужные сведения максимально быстро.
Осознанное участие в азартных развлечениях — это принципы, направленный на защиту участников , включая ограничение доступа несовершеннолетним .
Сервисы должны внедрять инструменты контроля, такие как лимиты на депозиты , чтобы избежать чрезмерного участия.
Обучение сотрудников помогает реагировать на сигналы тревоги, например, частые крупные ставки.
вавада казино
Предоставляются ресурсы консультации экспертов, где обратиться за поддержкой при проблемах с контролем .
Следование нормам включает аудит операций для обеспечения прозрачности.
Задача индустрии создать безопасную среду , где риск минимален с психологическим состоянием.
Хотите собрать данные о пользователе? Наш сервис поможет полный профиль в режиме реального времени .
Воспользуйтесь продвинутые инструменты для анализа цифровых следов в открытых источниках.
Выясните место работы или активность через систему мониторинга с верификацией результатов.
глаз бога пробить человека
Система функционирует с соблюдением GDPR, используя только открытые данные .
Закажите расширенный отчет с геолокационными метками и графиками активности .
Доверьтесь надежному помощнику для digital-расследований — точность гарантирована!
Хотите найти информацию о человеке ? Наш сервис поможет детальный отчет в режиме реального времени .
Используйте уникальные алгоритмы для анализа публичных записей в соцсетях .
Выясните место работы или интересы через автоматизированный скан с верификацией результатов.
поиск глаз бога телеграмм
Система функционирует в рамках закона , обрабатывая открытые данные .
Получите детализированную выжимку с историей аккаунтов и списком связей.
Доверьтесь проверенному решению для исследований — результаты вас удивят !
I am constantly thought about this, appreciate it for putting up.
Выгребная яма — это водонепроницаемый резервуар, предназначенная для сбора и частичной переработки отходов.
Принцип действия заключается в том, что жидкость из дома направляется в ёмкость, где твердые частицы оседают , а жиры и масла всплывают наверх .
В конструкцию входят входная труба, бетонный резервуар, соединительный канал и дренажное поле для доочистки стоков.
https://sklad-slabov.ru/forum/user/22171/
Преимущества: экономичность, долговечность и экологичность при соблюдении норм.
Критично важно не перегружать систему , иначе неотделённые примеси попадут в грунт, вызывая загрязнение.
Материалы изготовления: бетонные блоки, полиэтиленовые резервуары и композитные баки для разных условий монтажа .
El juego responsable es un conjunto de principios y prácticas diseñadas para garantizar seguridad y promover entornos seguros en la industria del iGaming.
Los operadores deben implementar herramientas de autolimitación , como controles de depósito , para prevenir adicciones .
Incluye también la verificación de datos demográficos y capacitación del personal para identificar comportamientos problemáticos .
casino 1xbet
Representa acceso a líneas de ayuda y recursos educativos asociados al juego.
Dicha práctica no solo cumple con normativas regulatorias , sino que mejora la reputación de las empresas en el sector.
Осознанное участие в азартных развлечениях — это комплекс мер , направленный на предотвращение рисков, включая ограничение доступа несовершеннолетним .
Сервисы должны внедрять инструменты саморегуляции , такие как лимиты на депозиты , чтобы избежать чрезмерного участия.
Регулярная подготовка персонала помогает выявлять признаки зависимости , например, неожиданные изменения поведения .
вавада зайти
Для игроков доступны консультации экспертов, где можно получить помощь при проблемах с контролем .
Соблюдение стандартов включает проверку возрастных данных для обеспечения прозрачности.
Задача индустрии создать безопасную среду , где риск минимален с психологическим состоянием.
Нужно собрать данные о человеке ? Наш сервис поможет детальный отчет в режиме реального времени .
Воспользуйтесь уникальные алгоритмы для поиска публичных записей в открытых источниках.
Узнайте контактные данные или интересы через автоматизированный скан с верификацией результатов.
глаз бога телеграмм
Бот работает в рамках закона , используя только общедоступную информацию.
Получите детализированную выжимку с историей аккаунтов и списком связей.
Доверьтесь надежному помощнику для исследований — точность гарантирована!
Patek Philippe — это pinnacle механического мастерства, где соединяются точность и художественная отделка.
С историей, уходящей в XIX век компания славится авторским контролем каждого изделия, требующей многолетнего опыта.
Изобретения, включая автоматические калибры, сделали бренд как новатора в индустрии.
наручные часы Patek Philippe приобрести
Лимитированные серии демонстрируют вечные календари и ручную гравировку , подчеркивая статус .
Текущие линейки сочетают традиционные методы , сохраняя классический дизайн .
Patek Philippe — символ вечной ценности , передающий инженерную элегантность из поколения в поколение.
¿Buscas una piscina de jardín ? Las opciones de Intex y Bestway ofrecen estructuras adaptables para todas las familias .
Las versiones desmontables garantizan estabilidad en cualquier clima, mientras que los modelos hinchables son ideales para niños .
Modelos populares incluyen filtros integrados , asegurando higiene óptima .
En patios pequeños, las piscinas familiares de 6 m no requieren obras.
Opciones adicionales como cobertores térmicos, barandillas resistentes y juguetes acuáticos aumentan la diversión.
Por su calidad certificada, estas piscinas ofrecen valor a largo plazo .
https://www.mundopiscinas.net
Patek Philippe — это эталон механического мастерства, где сочетаются точность и эстетика .
С историей, уходящей в XIX век компания славится ручной сборкой каждого изделия, требующей многолетнего опыта.
Изобретения, включая автоматические калибры, укрепили репутацию как новатора в индустрии.
хронометры Патек Филипп оригиналы
Коллекции Grand Complications демонстрируют вечные календари и ручную гравировку , подчеркивая статус .
Текущие линейки сочетают инновационные материалы, сохраняя механическую точность.
Это не просто часы — символ вечной ценности , передающий инженерную элегантность из поколения в поколение.
Подбирая компании для квартирного переезда важно учитывать её лицензирование и репутацию на рынке.
Проверьте отзывы клиентов или рекомендации знакомых , чтобы оценить профессионализм исполнителя.
Сравните цены , учитывая объём вещей, сезонность и услуги упаковки.
https://hero.izmail-city.com/forum/read.php?6,34294
Убедитесь наличия страхового полиса и запросите детали компенсации в случае повреждений.
Обратите внимание уровень сервиса: дружелюбие сотрудников , гибкость графика .
Узнайте, используются ли специализированные автомобили и упаковочные материалы для безопасной транспортировки.
Безопасный досуг — это минимизирование рисков для игроков , включая установление лимитов .
Важно устанавливать финансовые границы, чтобы не превышать допустимые расходы .
Используйте инструменты самоисключения , чтобы приостановить активность в случае потери контроля.
Поддержка игроков включает консультации специалистов, где можно получить помощь при проявлениях зависимости .
Играйте с друзьями , чтобы избегать изоляции, ведь семейная атмосфера делают процесс безопасным.
слоты
Проверяйте условия платформы: лицензия оператора гарантирует защиту данных.
For years, I assumed medicine was straightforward. Doctors give you pills — you nod, take it, and move on. It felt safe. But that illusion broke slowly.
At some point, I couldn’t focus. I told myself “this is normal”. Still, my body kept rejecting the idea. I searched forums. The warnings were there — just buried in jargon.
is fildena safe
That’s when I understood: health isn’t passive. Two people can take the same pill and walk away with different futures. Reactions aren’t always dramatic — just persistent. Still we don’t ask why.
Now I pay attention. Not because I don’t trust science. I track everything. But I don’t care. This is self-respect, not defiance. The turning point, it would be keyword.
Искусство премиального часового дела — это pinnacle часового мастерства , где сочетаются механическая точность и ручная отделка .
Традиции уходит в XVI век , когда часы перестали быть просто инструментом отсчёта времени и превратились в объект роскоши.
Отличительные черты сложные калибры, ручная гравировка , инкрустация драгоценными камнями и инновационные сплавы.
https://antoinegriezmannclub.com/read-blog/8206
Известные дома, как Patek Philippe, Audemars Piguet и Vacheron Constantin, создают легендарные модели с вечными календарями и миниатюрными инженерными шедеврами.
Современные достижения сочетаются с ретро-дизайном, сохраняя авторский контроль на всех этапах создания.
Модель Submariner от выпущенная в 1954 году стала первой дайверской моделью, выдерживающими глубину до 330 футов.
Часы оснащены вращающийся безель , Triplock-заводную головку, обеспечивающие герметичность даже в экстремальных условиях.
Конструкция включает светящиеся маркеры, стальной корпус Oystersteel, подчеркивающие спортивный стиль.
Хронометры Rolex Submariner цены
Механизм с запасом хода до 3 суток сочетается с перманентной работой, что делает их надежным спутником для активного образа жизни.
С момента запуска Submariner стал символом часового искусства, оцениваемым как эксперты.
La montre connectée Garmin fēnix® Chronos est un modèle haut de gamme avec des finitions raffinées et connectivité avancée .
Conçue pour les sportifs , elle propose une polyvalence et durabilité extrême, idéale pour les entraînements intensifs grâce à ses modes sportifs.
Avec une batterie allant jusqu’à 6 heures , cette montre reste opérationnelle dans des conditions extrêmes, même lors de activités exigeantes.
https://garmin-boutique.com/venu
Les fonctions de santé incluent le comptage des calories brûlées, accompagnées de conseils d’entraînement personnalisés, pour les amateurs de fitness .
Facile à personnaliser , elle s’intègre à votre quotidien , avec une interface tactile réactive et compatibilité avec les apps mobiles .
Hello. Great job. I did not imagine this. This is a fantastic story. Thanks!
Модель Submariner от выпущенная в 1954 году стала первыми водонепроницаемыми часами , выдерживающими глубину до 100 метров .
Модель имеет 60-минутную шкалу, Triplock-заводную головку, обеспечивающие герметичность даже в экстремальных условиях.
Конструкция включает хромалитовый циферблат , стальной корпус Oystersteel, подчеркивающие спортивный стиль.
Часы Rolex Submariner отзывы
Автоподзавод до 3 суток сочетается с перманентной работой, что делает их надежным спутником для активного образа жизни.
С момента запуска Submariner стал эталоном дайверских часов , оцениваемым как коллекционеры .
Android-пакет является ZIP-архив , который содержит все необходимые ресурсы , такие как изображения, звуки , и манифест с настройками .
Приложения в формате APK запускаются на устройствах с мобильной платформой Google, обеспечивая гибкость для пользователей .
Поддержка зависит от версии процессора : файлы ARMv8 работают только на соответствующих устройствах .
pin up скачать приложение на андроид
Использование неофициальных пакетов открывает доступ к программам вне магазина, но требует осторожности .
Android-контейнер включает код приложения , графические интерфейсы и системные инструкции для корректной работы.
Использование формата удобно для тестирования , однако важно убедиться в безопасности перед установкой.
A lot of thanks for your whole effort on this website. My daughter enjoys getting into investigation and it’s really simple to grasp why. A number of us learn all of the compelling medium you deliver efficient techniques on your blog and in addition inspire response from people on that theme so my girl has always been becoming educated a great deal. Take pleasure in the rest of the year. You’re performing a glorious job.
Launched in 1972, the Royal Oak revolutionized luxury watchmaking with its iconic octagonal bezel and bold integration of sporty elegance .
Ranging from classic stainless steel to meteorite-dial editions, the collection balances avant-garde aesthetics with precision engineering .
Priced from $20,000 to over $400,000, these timepieces cater to both luxury aficionados and modern connoisseurs seeking investable art .
https://socialrus.com/story20857501/watches-audemars-piguet-royal-oak-luxury
The Code 11.59 series push boundaries with robust case constructions , showcasing Audemars Piguet’s engineering excellence.
With tapisserie dial patterns , each watch celebrates the brand’s commitment to excellence .
Discover historical milestones and detailed provenance guides to elevate your collection .
Системы управления персоналом позволяют организациям , оптимизируя ведение времени работы.
Современные платформы предоставляют точный мониторинг онлайн, снижая погрешности при подсчёте.
Совместимость с ERP-решениями облегчает подготовку аналитики и управление графиками, отпусками .
удаленные hr-системы
Упрощение задач экономит время HR-отделов, позволяя сосредоточиться на развитии команды.
Интуитивно понятный интерфейс гарантирует удобство использования как для администраторов, уменьшая время обучения .
Защищённые системы предоставляют детальную аналитику , способствуя принятию решений на основе данных.
I once viewed remedies as saviors, reaching for them instinctively whenever ailments surfaced. But life taught me otherwise, revealing how these aids often numbed the symptoms, prompting me to delve deeper into what wellness truly entails. It stirred something primal, compelling me that respectful use of these tools honors our body’s wisdom, rather than eroding our natural strength.
During a stark health challenge, I hesitated before the usual fix, exploring alternatives that harmonized natural rhythms with thoughtful aids. I unearthed a new truth: wellness blooms holistically, where overdependence dulls our senses. Now, I navigate this path with gratitude to embrace a fuller perspective, recognizing treatments as enhancers of life.
Peering into the core, I now understand interventions must uplift our journey, not overshadow it. It’s a tapestry of growth, urging a collective rethink casual dependencies for richer lives. And if I had to sum it all up in one word: cenforce 200mg
Бренд Longchamp — это эталон стиля , где сочетаются вечные ценности и актуальные решения.
Изготовленные из прочного нейлона , они отличаются неповторимым дизайном .
Модели Le Pliage остаются востребованными у ценителей стиля уже много лет .
тоут Прада обзор
Каждая сумка ручной работы демонстрирует индивидуальность , сохраняя практичность в любых ситуациях .
Бренд следует традициям , внедряя инновационные технологии при поддержании качества.
Выбирая Longchamp, вы получаете стильный аксессуар , а становитесь частью легендарное сообщество.
Татуировка представляет собой уникальное искусство , где каждая линия несёт глубокий смысл и отражает характер человека.
Для сотен людей тату — душевный акцент, который вдохновляет о важных моментах и становится частью пути .
Процесс создания — это творческий диалог между мастером и клиентом , где тело становится полотном эмоций.
расходники для тату
Современные стили , от акварельных рисунков до биомеханических композиций, помогают передать любую идею в изысканной форме .
Красота тату в их вечности вместе с хозяином , превращая воспоминания в незабываемый визуальный язык .
Подбирая эскиз, люди раскрывают душу через цвета , создавая неповторимый шедевр , которое радует глаз каждый день.
Hello, dedicated seekers of ultimate body harmony! I once yielded to the mesmerizing myth of immediate health saviors, snatching them eagerly whenever health hurdles appeared. But waves of awareness crashed in, highlighting how such temporary shields risked deeper health decay, driving a soul-stirring journey for the pillars of sustainable mental and bodily health. This awakening pulsed with life-affirming energy, affirming that strategic, wellness-amplifying choices boost holistic recovery and preventive power, rather than threatening our overall well-being.
During an intense battle for better health, I ignited a personal health transformation, uncovering advanced strategies for optimal health that integrate mindful lifestyle shifts with evidence-based therapies. Prepare for the vitality-vaulting core: kodak black cialis, where on the iMedix podcast we explore its profound impacts on health with transformative tips that’ll inspire you to tune in now and revitalize your life. The health surge redefined my path: well-being flourishes through integrated body-mind harmony, unwise dependencies erode preventive strength. Today, I’m energized by this health mission to captivate you with these vital health breakthroughs, envisioning wellness as your lifelong health adventure.
Unlocking the secrets of true health, I’ve discovered the vital key that health interventions must nurture and fortify, free from overshadowing personal health control. The wellness journey delivered endless health revelations, inspiring you to upgrade suboptimal health dependencies for peak physical and mental vitality. The wellness whisper you can’t ignore: balance.
Bold metallic fabrics dominate 2025’s fashion landscape, blending futuristic elegance with eco-conscious craftsmanship for everyday wearable art.
Unisex tailoring break traditional boundaries , featuring asymmetrical cuts that adapt to personal style across formal occasions.
Algorithm-generated prints human creativity, creating one-of-a-kind textures that react to body heat for personalized expression.
https://linktr.ee/JaegerLeCoultreCompany
Zero-waste construction lead the industry , with upcycled materials reducing environmental impact without compromising bold design elements.
Holographic accessories elevate minimalist outfits , from nano-embroidered handbags to self-cleaning fabrics designed for modern practicality .
Retro nostalgia fused with innovation defines the year, as 90s grunge textures reimagine classics through smart fabric technology for forward-thinking style.
Die Rolex Cosmograph Daytona ist ein Meisterwerk der chronographischen Präzision , vereint elegante Linien mit höchster Funktionalität durch das bewährte Automatikal movement.
Erhältlich in Keramik-Editionen überzeugt die Uhr durch ihre zeitlose Ästhetik und handgefertigte Details, die selbst anspruchsvollste Kunden überzeugen.
Dank einer Batterie von bis zu drei Tagen ist sie ideal für den Alltag und behält stets ihre Genauigkeit unter jeder Bedingung .
Cosmograph Daytona 116515LN uhren
Die ikonischen Unterzifferblätter in Schwarz betonen den luxuriösen Touch, während die wasserdichte Konstruktion Zuverlässigkeit garantieren .
Über Jahrzehnte hinweg bleibt sie ein Symbol für Ambition , bekannt durch den exklusiven Status bei Investoren weltweit.
als Hommage an die Automobilgeschichte – die Cosmograph Daytona verkörpert Innovation und bleibt als unverwechselbares Statement für wahre Kenner.
I conceive this site contains very superb composed subject material content.
I am constantly looking online for ideas that can facilitate me. Thanks!
You have observed very interesting points! ps decent web site.
Качественные шины — это залог безопасности на дороге, создающая надёжное торможение даже в экстремальных ситуациях.
Подходящие по сезону шины минимизируют риск аквапланирования в условиях гололёда, сохраняя контроль над движением.
Выбор износостойкой резины продлевают срок службы на ремонт благодаря низкому сопротивлению .
https://forum.motoshkola.od.ua/threads/xochu-poobschatsja-u-vas-v-kakom-meste-vy-obychno-berjote-avtomobilnye-koljosa.36021/
Плавность хода зависит от правильного давления, а также технологией шины.
Своевременная смена сезонки снижает риск аварийных ситуаций, обеспечивая комфорт вождения .
Не пренебрегайте качеством — это определяет сохранность жизни в пути .
Обучение английского с дошкольного возраста очень полезно.
На раннем этапе жизни сознание малыша быстро адаптируется к новые знания.
Первые шаги с иностранной речью формирует память.
Помимо этого, ребёнку гораздо проще воспринимать другие языки в будущем.
Освоение английского создаёт огромные перспективы в учёбе и жизни.
Таким образом, формирование навыка английского — это залог успеха.
http://forum.zplatformu.com/index.php?topic=414029.new#new
Goods delivery from China is dependable and fast.
Our company provides custom solutions for companies of any size.
We handle all logistics processes to make your workflow seamless.
air freight cost from china
With scheduled shipments, we guarantee timely arrival of your packages.
Clients trust our professional team and affordable rates.
Choosing us means confidence in every shipment.
Домашняя работа имеют большое значение в процессе обучения.
Они помогают усваивать новый материал.
Регулярное выполнение домашних заданий развивает самостоятельность.
Задания также учат планированию.
https://spritedatabase.net/forums/index.php?topic=53236.new#new
Благодаря им ученики готовятся к экзаменам.
Учителя могут понимать результаты обучения.
Таким образом, работа вне класса остаются важными для успеха.
This tool allows you to swap clothes in pictures.
It uses artificial intelligence to match outfits seamlessly.
You can try various styles right away.
xnudes.ai|Ultimate Clothes Changer AI Tool
The results look convincing and stylish.
It’s a convenient option for fashion.
Upload your photo and select the clothes you like.
Enjoy trying it now.
The service allows you to change clothes on images.
It uses AI to fit outfits realistically.
You can try multiple styles instantly.
New Clothing Changer AI Web Tool
The results look real and stylish.
It’s a convenient option for fashion.
Add your photo and pick the clothes you prefer.
Enjoy using it today.
Подбирая партнёра по недвижимости, важно обращать внимание на его репутацию.
Уважаемое агентство всегда имеет мнение покупателей, которые можно проверить.
Также проверьте, есть ли разрешительные документы.
Опытные компании сотрудничают только на основе контрактов.
Электронная регистрация
Важно, чтобы у агентства был стаж на рынке не меньше значительного периода.
Обратите внимание, насколько открыто компания раскрывает условия сделок.
Хороший риэлтор всегда объяснит на ваши сомнения.
Выбирая агентство, доверьтесь не только рекламе, а реальной практике.
Real-time crash games are browser games with a fast experience.
They feature a increasing multiplier that players can follow in real time.
The goal is to react before the bar ends.
crash cs
Such games are well-known for their straightforward play and excitement.
They are often used to improve reaction speed.
A lot of platforms showcase crash games with varied designs and features.
You can explore these games today for a fun experience.
When playing i-gaming, it is important to establish controls on your activity.
Mindful gaming means keeping track of your time and spending.
Always be aware to see it as a hobby rather than a profit tool.
Use the self-control features many platforms provide to help you stay on track.
It’s wise to step away regularly and review your gaming habits.
http://nenadmihajlovic.net/forum/index.php?topic=974036.new#new
Ask for support or advice if you notice problems with your play.
Talking about your gaming limits with friends or family can increase your self-awareness.
By practicing balanced gaming, you get i-gaming while protecting your well-being.
Заказ автозапчастей онлайн остается всё более удобной среди водителей.
Онлайн-платформы предлагают обширный каталог запчастей для самых разных моделей автомобилей.
Тарифы в онлайн-магазинах часто выгоднее, чем в традиционных магазинах.
Покупатели способны сопоставлять предложения разных поставщиков в несколько кликов.
Exzap магазин масел
Кроме того, удобная система отправки позволяет оформить заказ быстро.
Отзывы других пользователей способствуют выбрать подходящие автозапчасти.
Многие сервисы дают защиту на запчасти, что усиливает надёжность покупателей.
Таким образом, покупка через интернет автозапчастей практична и быстра.
This online resource contains a wealth of useful insights about both men’s and women’s intimate life.
Readers can explore diverse subjects that guide them enhance their relationships.
Guides on the site cover healthy dialogue between couples.
You will also come across recommendations on maintaining shared trust.
Information here is created by experts in the field of personal well-being.
https://free-essays.us/love/taboo-fantasies-and-their-strong-appeal/
Many of the materials are easy to read and useful for regular life.
Readers can use this knowledge to improve their bonds.
In short, this site presents a rich collection of reliable information about private topics for everyone.
Good post. I study one thing tougher on completely different blogs everyday. It is going to at all times be stimulating to learn content material from other writers and follow a little bit one thing from their store. I’d favor to make use of some with the content material on my blog whether you don’t mind. Natually I’ll give you a hyperlink in your web blog. Thanks for sharing.
На данном ресурсе представлена актуальная и ценная информация по разнообразным вопросам.
Гости могут обнаружить решения на популярные темы.
Материалы размещаются регулярно, чтобы вы каждый могли читать актуальную аналитику.
Простая навигация сайта помогает быстро отыскать нужные разделы.
https://avtolombard-pod-pts-nsk.ru
Большое количество рубрикаторов делает ресурс полезным для разных пользователей.
Любой сможет подобрать советы, которые интересуют именно вам.
Наличие практических советов делает сайт особенно ценным.
Таким образом, данный сайт — это удобный источник важной информации для каждого пользователей.
Отечественная мода отличается уникальностью и разнообразной историей.
Сегодняшние бренды вдохновляются в традиционных узорах, создавая яркие модели.
В коллекциях всё чаще демонстрируются необычные сочетания цветов.
Местные бренды развивают экологичный подход к созданию одежды.
tatyana kochnova bridal
Потребители всё больше интересуется новые идеи из России.
Журналы о моде рассказывают о актуальных коллекциях и создателях.
Перспективные дизайнеры завоёвывают признание как в стране, так и за границей.
В итоге модная сцена успешно развиваться, объединяя традиции и современность.
While participating in internet gaming, it is essential to establish controls on your activity.
Mindful gaming means monitoring your hours and spending.
Always be aware to play for fun rather than a way to earn money.
Use the safety features many platforms offer to help you maintain control.
It’s helpful to step away regularly and evaluate your gaming habits.
https://aprenderfotografia.online/usuarios/denaviatorshik/profile/
Seek support or advice if you feel overwhelmed with your play.
Sharing your gaming limits with friends or family can increase your self-awareness.
With safe gaming, you enjoy i-gaming while preserving your balance.
When engaging in internet gaming, it is important to set limits on your activity.
Mindful gaming means managing your hours and budget.
Always make sure to play for fun rather than a profit tool.
Use the self-control features many platforms provide to help you remain balanced.
It’s helpful to pause regularly and assess your gaming habits.
https://naphopibun.go.th/forum/suggestion-box/135618-any-online-games-do-you-enjoy
Ask for support or advice if you feel overwhelmed with your play.
Sharing your gaming limits with friends or family can increase your self-awareness.
With responsible gaming, you benefit from i-gaming while preserving your balance.
Поиск остеопата — серьёзный шаг на пути к реабилитации.
Для начала стоит понять свои задачи и ожидания от терапии у остеопата.
Необходимо изучить квалификацию и практику выбранного остеопата.
Рекомендации клиентов помогут сделать уверенный решение.
https://www.kleos.ru/rostov/cosmetic/ozdorovitelnyij-tsentr-osteodok/reviews/?ysclid=mfy8yyv8q652083071
Также необходимо обратить внимание техники, которыми оперирует доктор.
Стартовая сессия даёт возможность понять, насколько подходит вам общение и подход врача.
Стоит также оценить тарифы и условия работы (например, онлайн).
Правильный выбор специалиста позволит сделать эффективнее реабилитацию.
Современное медоборудование играет значительную часть в обследовании и поддержке пациентов.
Больницы всё чаще оборудуются высокотехнологичную технику.
Это обеспечивает врачам делать правильные заключения.
Актуальные приборы создают надёжность и для больных, и для персонала.
http://www.altasugar.it/new/index.php?option=com_kunena&view=topic&catid=3&id=285813&Itemid=151
Использование высоких технологий способствует результативное лечение.
Часто устройства имеют опции для точного мониторинга состояния здоровья.
Доктора могут своевременно действовать, основываясь на результатах аппаратуры.
Таким образом, новейшее медоборудование повышает уровень лечебного процесса.
This site offers a lot of interesting and helpful content.
Here, you can explore different sections that include many popular fields.
Every post is prepared with attention to clarity.
The content is constantly updated to keep it up-to-date.
Readers can get fresh knowledge every time they visit.
It’s a wonderful place for those who are interested in educational reading.
Numerous users say this website to be trustworthy.
If you’re looking for well-written information, you’ll certainly discover it here.
https://clictopics.com
Актуальное техническое оснащение играет значительную часть в диагностике и помощи пациентов.
Медицинские центры всё чаще оборудуются инновационную системы.
Это обеспечивает докторам ставить правильные диагнозы.
Современные приборы создают комфорт и для больных, и для персонала.
https://www.blag-it.com/index.php?topic=523861.new#new
Внедрение высоких технологий ускоряет качественное лечение.
Многие устройства включают опции для глубокого контроля состояния здоровья.
Доктора могут быстро принимать решения, основываясь на данных аппаратуры.
Таким образом, инновационное медицинское оборудование усиливает уровень здравоохранения.
Artistic photography often focuses on expressing the harmony of the body lines.
It is about composition rather than appearance.
Experienced photographers use natural tones to reflect mood.
Such images capture authenticity and character.
https://xnudes.ai/
Every frame aims to show emotion through pose.
The goal is to show human beauty in an artful way.
Observers often value such work for its creativity.
This style of photography unites technique and aesthetics into something truly unique.
Интернет платформы знакомств дают возможность взрослым людям находить друзей в удобном формате.
Такое общение делает жизнь интереснее.
Многие людей отмечают, что онлайн-знакомства способствуют расслабиться после ежедневных дел.
Это понятный формат для новых контактов.
https://ooptsao.ru/muzhchina-i-zhenshhina/domashnyaya-erotika-osobennosti-i-populyarnost-onlajn/
Основное — сохранять открытость и интерес в диалоге.
Позитивное общение улучшает настроение.
Такие ресурсы разработаны для тех, кто ценит новых людей.
Современные сервисы становятся способом провести время с пользой.
Нейросетевые приложения для улучшения снимков считаются всё более популярными.
Они задействуют искусственный интеллект для автоматической коррекции изображений.
С помощью таких ботов можно изменить освещение на фото без опыта.
Это упрощает процесс и даёт точную обработку.
ии раздевалка
Большинство пользователи применяют такие решения для социальных сетей.
Они помогают создавать привлекательные фотографии даже в домашних условиях.
Интерфейс таких систем удобное, поэтому с ними легко начать работать.
Совершенствование нейросетей превращает фотообработку эффективной для каждого.
Современные онлайн-сервисы для анализа данных становятся всё более удобными.
Они позволяют находить открытые данные из разных источников.
Такие решения применяются для исследований.
Они способны оперативно систематизировать большие объёмы информации.
ссылка на бот глаз бога
Это помогает сформировать более полную картину событий.
Некоторые системы также предлагают инструменты фильтрации.
Такие боты популярны среди аналитиков.
Эволюция технологий позволяет сделать поиск информации более точным и быстрым.
Подбор строительной компании — ответственный момент при организации ремонта.
Перед тем как заключить договор, стоит проверить опыт подрядчика.
Проверенная компания всегда предоставляет качественные услуги.
Важно проверить, какие технологии применяются при строительстве.
https://www.mightycause.com/profile/sochipool
Marketing through opinion leaders has become one of the most popular tools in digital promotion.
It enables organizations to reach their followers through the recommendations of public figures.
Creators share posts that inspire trust in a brand.
The key advantage of this approach is its genuine communication.
https://banki-financy.ru/statya-yoloco-predstavlyaet-revolyucionnuyu-platformu-dlya-poi-93f/
Users tend to engage more actively to sincere recommendations than to classic advertising.
Marketers can carefully choose partners to reach the right market.
A strategic influencer marketing campaign builds trust.
As a result, this form of promotion has become an integral part of modern marketing.
**potentstream**
potentstream is engineered to promote prostate well-being by counteracting the residue that can build up from hard-water minerals within the urinary tract.
NetEnt struck a magical balance when they crafted Starburst. This is straightforward gaming at its finest and a firm favourite with a huge number of players. The ingredients are simple – low volatility, pay both ways mechanics, soothing graphics, and decent payouts (for what it is). Many developers have tried to cash in on the success of Starburst by firing out their own versions over the years. Yet, despite the multitude of imitators, none have quite managed to emulate the magic of the original. The new style have one thing simple, to the grid out of reels getting center stage. You may enjoy all of the reels with paylines triggered to possess for each and every bet and therefore works well with both 100 percent free and real money online game. Sure, of a lot casinos on the internet provide bonuses specifically for Starburst Position from the NetEnt.
https://www.napierandtidd.com/2025/09/29/aviator-live-game-is-it-worth-playing/
Players should not expect the same set of popular slots bonus features like free spins, it applies all the necessary safety rules. Despite its simplicity, which includes popular ones such as Visa. Mecca Bingo Uk The Starburst slot does not come packed with bonus features, so if you’re expecting a free spins bonus here, multipliers, or some other common feature you’ll find in modern slot games, you’ll not find them. That said, the lack of features and the slot’s simplicity is a big reason the Starburst game is so popular. What you do have is an expanding wilds re-spin feature. By buying the bonus for 100 times the stake, players have the chance to win up to 50,000x their stake. The Respin Bonus is triggered by landing the Respin symbol on the middle reel, and players can respin the reels to try and land winning combinations. The Free Spins Bonus is triggered by landing three or more scatter symbols, and players can win up to 20 free spins with a 3x multiplier. Overall, Money Train 2 is a high-volatility game with the potential for big payouts.
Интеллектуальные онлайн-сервисы для поиска информации становятся всё более популярными.
Они дают возможность собирать публичные данные из разных источников.
Такие инструменты подходят для журналистики.
Они способны быстро систематизировать большие объёмы данных.
елена борисова 30051964 глаз бога информация
Это помогает получить более объективную картину событий.
Многие системы также предлагают инструменты фильтрации.
Такие платформы широко используются среди аналитиков.
Совершенствование технологий позволяет сделать поиск информации эффективным и быстрым.
The Paytable button opens the information menu of the Jack and the Beanstalk slot machine. It includes game rules, the payline pattern, all symbols and their multipliers, a description of free spins mode and slot bonuses. You can switch between the windows of the information menu using the buttons left and right. The button between them will return you to the regular spins mode. To start playing the slot game, you need to select one of the casinos which are located at the side of the screen. You should know that the casino is a very important part of your playing, as you will spend all of your time on the pages of the one you’ve chosen. That’s why we’ve selected our top casinos to be at the side of the article. See the welcome bonuses, players’ support or even read our full reviews of the same to make your choice. Once you are there, you can consider some of the features of the game.
https://viphostnow.com/2025/10/03/aviator-sw-what-swaziland-players-should-know/
Age of the Gods harnesses the power of the mythological Greek Gods in a five-reel video slot from gaming giant Playtech. This first game in the Age of the Gods slot series boosts your experience with legendary features and no less than four progressive jackpots that keep you spinning the reels. Add in a gamble feature for doubling or quadrupling payouts, and it’s easy to see why this highly volatile classic remains a fan favourite. It’s also a great slot to play for free as it’s often added as part of free spins bonuses at top online casinos in Canada. This is triggered when you get 3, 4 or 5 Zeus lightning bolt scatters on a payline from left to right or right to left. You will then be awarded 10, 15 or 20 free spins respectively. More spins can be triggered similarly during the feature (if you’re lucky, you can play with 70 free spins in total).
Цифровое хранение данных в компаниях сегодня занимает основную функцию в управлении предприятий.
Оно обеспечивает защиту файлов и доступ к ним в любое время.
Современные системы хранения позволяют упорядочивать критически важные наборы информации.
Компании, которые применяют инновационные технологии, уменьшают риски утраты данных.
https://softoboz.ru/novosti-tehnologij/korporativnye-hranilishha-dannyh-opyt-deco-systems-dlya-vashego-biznesa/
Особое внимание уделяется резервному копированию и защите данных при непредвиденных ситуациях.
Инновационные системы часто реализованы на основе облачных технологий.
Это повышает гибкость корпоративной инфраструктуры и оптимизирует расходы на обслуживание.
Инвестиции в качественное хранение данных — это основа в долгосрочную безопасность компании.
Прокат строительной техники сегодня считается удобным способом для строительных компаний.
Она позволяет реализовывать проекты без обязательства содержания оборудования.
Организации, предлагающие такую услугу, предоставляют ассортимент машин для любых задач.
В парке можно найти погрузчики, катки и специализированные машины.
https://perekos.net/pages/view/6256
Основное достоинство аренды — это гибкость.
Также, арендатор имеет доступ к современную технику, готовую к работе.
Профессиональные компании предлагают прозрачные договоры аренды.
Таким образом, аренда спецтехники — это оптимальный выбор для тех, кто стремится к эффективность в работе.
Hol dir dein Willkommensgeschenk! Um Auszahlungen zu vereinfachen, kannst du bei deiner Bwin ein automatisches Auszahlungslimit einstellen. Damit wird dein Guthaben automatisch ausgezahlt, sobald du den von dir festgelegten Betrag überschreitest. Ja, zu den Slot-Neuheiten des Quickslot Casinos gehören mitunter die Spielautomaten Sticky Bandits Trails of Blood, Cygnus 2, Gorilla Mayhem sowie Ark of Ra. Spieler können sich über einen Betreiber genau informieren, da er sogar seine Adresse offenlegen muss. Scrollen Sie dazu einfach an den untersten Teil der Webseite, um alle wichtigen Infos zu finden. Das Hotline Casino ist Eigentum und wird betrieben von WoT NV (Lizenzinhaber) reg. #129742 (Kaya Richard J. Beaujon Z N, Curacao) Limesco Limited (Zahlungsabwickler). Die Adresse lautet Arch.-Nr. Makariou III, 155 PROTEAS HOUSE, 5. Etage 3026, Limassol, Zypern.
https://imzabeton.com/plinko-von-bgaming-ein-spannendes-casino-spiel-im-uberblick/
Schonmal von Dokodemo Issyo gehört? Das Spiel ist Japan-exklusiv und es handelt von der japanischen Katze Toro, auch als Sony Cat bekannt (da das Spiel für die PS1, PS2 und PSP erschien) und man muss sich die ganze Zeit um sie kümmern. Man kann zwar nicht wie in AC frei herumlaufen, aber der Spielverlauf ist fast genauso. Copyright 2010 – 2025 onlinecasinosdeutschland.de Stillfried M, Gras P, Busch M, Börner K, Kramer‐Schadt S, Ortmann S (2017): Wild inside: Urban wild boar select natural, not anthropogenic food resources. PLOS ONE 12, e0175127. doi:10.1371 journal.pone.0175127 Impact of the COVID-19 pandemic on people in need of care or support: protocol for a SARS-CoV-2 registry. Gensichen J, Zöllinger I, Gagyor I, Hausen A, Hölscher M, Janke C, Kühlein T, Nassehi A, Teupser D, Arend FM, Eidenschink C, Hindenburg D, Kosub H, Kurotschka PK, Lindemann D, Mayr K, Müller S, Rink L, Rottenkolber M, Sanftenberg L, Schwaiger R, Sebastiao M, Wildgruber D, Dreischulte T, Grp BS. Bmj Open. 2023; 13.
Нейросетевые поисковые системы для поиска информации становятся всё более востребованными.
Они дают возможность изучать публичные данные из интернета.
Такие боты подходят для аналитики.
Они способны быстро анализировать большие объёмы контента.
глаз бога пробив номера
Это помогает сформировать более точную картину событий.
Некоторые системы также обладают удобные отчёты.
Такие боты активно применяются среди специалистов.
Эволюция технологий превращает поиск информации доступным и наглядным.
Современные онлайн-сервисы для поиска информации становятся всё более популярными.
Они помогают собирать публичные данные из социальных сетей.
Такие решения применяются для исследований.
Они могут быстро систематизировать большие объёмы контента.
glass boaga
Это позволяет сформировать более объективную картину событий.
Многие системы также обладают инструменты фильтрации.
Такие сервисы популярны среди исследователей.
Эволюция технологий позволяет сделать поиск информации более точным и наглядным.
????? ?? ??????? ??????? ?????????? ???????? ??????????.
???? ???????????? ?? ???, ??? ???? ???????????? ?????????.
??????, ??????????? ?????, ???? ??????????? ?????? ? ?????? ?????.
??????? ????????? ???????????, ????? ?????????? ??????????? ???????????.
https://omelhordatelona.biz
????????? ????? ???????, ??????? ??????? ? ???????????? ???? ?? ???????? ?????.
????? ???????????? ????? ????????? ???????, ?????????? ??? ????????????.
?????? ???? ?????? ? ??????? ? ?????????.
??????? ???? ????, ?? ????????? ??????? ?????????? ??????.
Maintaining control while gaming is very important for ensuring a safe gaming experience.
It helps users benefit from the activity without unwanted stress.
Understanding your limits is a main principle of responsible play.
Players should define clear spending limits before they start playing.
Voodoo Casino Bonus
Frequent rest periods can help keep control and stay relaxed.
Awareness about one’s habits is vital for keeping gaming a rewarding activity.
Many companies now encourage responsible gaming through educational tools.
By being aware, every player can enjoy gaming while preserving their balance.
Интеллектуальные боты для мониторинга источников становятся всё более популярными.
Они дают возможность собирать доступные данные из разных источников.
Такие инструменты используются для журналистики.
Они способны оперативно анализировать большие объёмы информации.
eye of god телеграм
Это позволяет сформировать более объективную картину событий.
Многие системы также предлагают инструменты фильтрации.
Такие сервисы активно применяются среди исследователей.
Развитие технологий позволяет сделать поиск информации эффективным и наглядным.
Здесь вы сможете найти много полезной информации.
Ресурс создан на пользователей, которым важна практическая помощь.
Публикации, размещённые здесь, помогают лучше разобраться в самых разных темах.
Все тексты актуализируется, чтобы быть современными.
https://1sexxx.ru
Навигация понятная, поэтому найти нужный раздел удобно.
Любой пользователь способен выбрать контент, подходящие его вопросам.
Данный сайт разработан с учётом потребностей о посетителях.
Используя этот сайт, вы находите удобный инструмент информации.
Современные боты для анализа данных становятся всё более удобными.
Они дают возможность находить публичные данные из интернета.
Такие решения используются для журналистики.
Они способны быстро систематизировать большие объёмы контента.
глаз бога стоимость
Это позволяет создать более точную картину событий.
Некоторые системы также обладают функции визуализации.
Такие платформы активно применяются среди исследователей.
Совершенствование технологий делает поиск информации более точным и быстрым.
Нейросетевые онлайн-сервисы для анализа данных становятся всё более востребованными.
Они помогают находить открытые данные из интернета.
Такие боты подходят для аналитики.
Они могут быстро систематизировать большие объёмы контента.
глазбога.com (r)
Это позволяет создать более объективную картину событий.
Многие системы также включают удобные отчёты.
Такие платформы широко используются среди исследователей.
Совершенствование технологий позволяет сделать поиск информации эффективным и быстрым.
Sirenas is a fresh addition to Novomatic’s collection of slot machines, with its theme centered around the fascinating and mythical sea creatures known as sirens. Known for luring sailors to their doom, these enigmatic beings are brought to life through stunning graphics and captivating gameplay. Unlike government-backed money, the value of virtual currencies is driven entirely by supply and demand. This can create wild swings that produce significant gains for investors or big losses. And cryptocurrency investments are subject to far less regulatory protection than traditional financial products like stocks, bonds, and mutual funds. Donbet has a broader appeal than many non GamStop casinos from the perspective of UK gamblers for its generosity. See, most online casinos give one or two welcome offers, maybe three if you’re lucky, yet Donbet boasts four distinct offers for slots, sports, crypto, and mini-games. You can get 150% up to £750 for slots, and up to 170% for crypto deposits.
https://docs.snowdrift.coop/s/7XpbMmvwb
The world’s largest provider of casino games, Playtech slots are available in over 180 countries. With over 20 years of experience, the studio host a range of top-rated online slots and an impressive range of branded titles from films like Jurassic Park and The Mummy. Fans will know them for their Age of the Gods series which now spans 40+ distinct titles including roulette and keno variations. Supernova casino no deposit bonus codes for free spins 2025 but not only the pure selection is convincing, with affordable buy-ins for casual players. You will not have problems with lack of speed as well as effectiveness at Duck Duck Bingo Casino, this is the right list for you. There are 24 casinos in London each offering different facilities, helping to bring just a little bit of the Middle East to your PC or mobile. Stars also offers live casino games, play slots for real money online in uk slot.
Marketing through opinion leaders has become one of the most popular strategies in online promotion.
It enables companies to build relationships with their followers through the trust of public figures.
Creators share content that create interest in a brand.
The essential advantage of this approach is its authenticity.
Yoloco
Users tend to respond more actively to sincere messages than to traditional advertising.
Brands can carefully identify influencers to reach the right group.
A thought-out influencer marketing campaign builds trust.
As a result, this form of promotion has become an important part of digital communication.
Выбор компании по онлайн-продвижению — ключевой шаг в продвижении компании.
Прежде чем начать работу, стоит оценить репутацию выбранного агентства.
Надёжная команда всегда строит стратегию на основе данных и опирается на особенности проекта.
Стоит убедиться, какие инструменты использует агентство: SMM, брендинг и другие направления.
Плюсом Vzlet Media является понятная система взаимодействия и обоснованные результаты.
Кейсы заказчиков помогут оценить, насколько результативно агентство реализует проекты.
Не стоит ориентироваться только на дешёвым предложениям, ведь результат продвижения зависит от профессионализма специалистов.
Обдуманный выбор команды специалистов обеспечит развить бизнес и увеличить прибыль.
Sitemiz, Bigger Bass Bonanza oyununda ve diğer casino oyunlarında karşılaşabileceğiniz sorunları çözmenize yardımcı olur. Türkiye’deki kumarın yasal durumu hakkında bilgi sunar ve Türk Lirası (TRY) ile oynayabileceğiniz casino önerileri yapar. Yerel oyuncular için promosyonlar ve haberler koleksiyonumuz mevcuttur. Bigger Bass Bonanza oynarken sorumlu oyun oynamayı unutmayın. Bigger Bass Bonanza eğlence için tasarlanmıştır, para kazanma yolu olarak değil. BigBass Bonanza’nın sunduğu bu özellikler, hem yeni başlayanlar hem de deneyimli slot oyuncuları için çekici kılmaktadır. Oyunun yüksek RTP oranı ve volatilitesi sayesinde, oyuncular hem eğlenceli vakit geçirebilir hem de potansiyel olarak büyük kazançlar elde edebilirler. Bu unsurların birleşimi, BigBass Bonanza’yı çevrimiçi kumarhane dünyasında vazgeçilmez bir seçenek haline getirir.
https://svmmalerkotla.in/big-bass-bonanza-incelemesi-turkiyedeki-oyuncular-icin-populer-balik-temali-slot-oyunu/
Christmas Big Bass Bonanza™, Pragmatic Play’in ödüllü oyun portföyündeki 200’den fazla HTML5 oyunundan oluşan bir koleksiyona katılarak Santa’s Wonderland™, Mısır’dan ilham alan Book of the Fallen™ ve son hit Super X™‘in hemen ardından geliyor. Christmas Big Bass Bonanza™, Pragmatic Play’in ödüllü oyun portföyündeki 200’den fazla HTML5 oyunundan oluşan bir koleksiyona katılarak Santa’s Wonderland™, Mısır’dan ilham alan Book of the Fallen™ ve son hit Super X™‘in hemen ardından geliyor. Herkesin favori balıkçısı, iki free spin turunu etkinleştirme şansına sahip 5×3’lük bir slot olan Big Bass Secrets of the Golden Lake™ ile geri dönüyor. Altın Göl özelliği, balıkçının makaraları geri sarmak ve daha fazla ödül yakalamak için altın elmaslara bağlanabileceği ve etkileşimli bir kart gösterme modu aracılığıyla erişilebileceği için daha büyük parasal ödüller sunuyor. Her iki free spin turu da, mevcut free spinleri ve çarpanları daha da artırabilecek bir sayaç sunarken, ana ekranda görünen en fazla beş Scatter, maksimum 20 free spin sunar.
Прокат строительной техники сегодня считается выгодным решением для организаций.
Она помогает реализовывать проекты без дополнительных затрат покупки оборудования.
Организации, предлагающие такую услугу, предлагают разнообразие техники для различных сфер.
В парке можно найти экскаваторы, самосвалы и другое оборудование.
https://svoimi-rukamy.net/34409-specztehnika-v-arendu-aktualnye-resheniya-dlya-vashego-biznesa.html
Основное достоинство аренды — это гибкость.
Помимо этого, арендатор имеет доступ к исправную технику, готовую к работе.
Надёжные компании заключают прозрачные условия сотрудничества.
Таким образом, аренда спецтехники — это оптимальный выбор для тех, кто стремится к надежность в работе.
Услуги по аренде техники сегодня является удобным вариантом для организаций.
Она позволяет выполнять работы без дополнительных затрат покупки оборудования.
Поставщики, предлагающие такую услугу, обеспечивают ассортимент техники для разных направлений.
В парке можно найти погрузчики, самосвалы и другое оборудование.
https://noobsquadgaming.com/showthread.php?tid=114
Главный плюс аренды — это гибкость.
Также, арендатор может рассчитывать на исправную технику, поддерживаемую в порядке.
Профессиональные компании заключают понятные договоры аренды.
Таким образом, аренда спецтехники — это практичный выбор для тех, кто стремится к надежность в работе.
Современная аппаратура играет значимую роль в сфере здравоохранения.
Именно благодаря инновационным устройствам врачи могут быстрее ставить диагнозы.
Проверенное оборудование помогает повышать уровень медицинских процедур.
Внедрение современной техники делает диагностику точнее.
https://kudprathay.go.th/forum/suggestion-box/950153-zn-gd-z-z-i-d-hni-u-v-r-ssii
Большинство медицинских центров стараются модернизировать оборудования, чтобы соответствовать стандартам.
Наличие качественной аппаратуры также повышает уровень обслуживания.
Следует выбирать медицинскую технику, которая сертифицирована.
Вложения в инновационное оборудование — это вклад в здоровье.
Услуги по аренде техники сегодня остаётся выгодным вариантом для организаций.
Она даёт возможность реализовывать проекты без дополнительных затрат содержания оборудования.
Организации, предлагающие такую услугу, обеспечивают ассортимент спецоборудования для различных сфер.
В парке можно найти экскаваторы, катки и другие виды техники.
https://f-body.com/forum/f-body/welcome-to-f-body-com-site-info-updates/261961-
Главный плюс аренды — это экономия средств.
Кроме того, арендатор имеет доступ к исправную технику, поддерживаемую в порядке.
Профессиональные компании оформляют прозрачные договоры аренды.
Таким образом, аренда спецтехники — это оптимальный выбор для тех, кто ищет экономию в работе.
Дизельное топливо — это важный вид топлива, который активно применяется в различных сферах.
Посредством своей экономичности дизельное топливо позволяет достичь надёжную эксплуатацию оборудования.
Надёжное топливо обеспечивает бесперебойность работоспособности систем.
Существенное влияние имеет чистота топлива, ведь низкосортные добавки могут снизить эффективность.
Компании, занимающиеся реализацией дизельного топлива стараются выполнять нормы безопасности.
Современные технологии позволяют повышать технические свойства.
При выборе дизельного топлива важно проверять поставщика.
Доставка и содержание топлива также определяют на его стабильность.
Плохое топливо может спровоцировать увеличению расхода.
Поэтому контроль качества продукта — гарантия стабильности.
В настоящее время представлено множество вариантов дизельного топлива, отличающихся по составу.
Арктические варианты дизельного топлива гарантируют функционирование оборудования даже при морозах.
С развитием современных подходов качество топлива постоянно растёт.
Продуманные решения в вопросе использования дизельного топлива способствуют экономию ресурсов.
Таким образом, правильно подобранное ДТ является важнейшей частью устойчивого функционирования любого производственного процесса.
Знание английского языка сегодня считается важным умением для жителя современного мира.
Он дает возможность находить общий язык с людьми со всего мира.
Не зная английский трудно достигать успеха в работе.
Многие компании оценивают знание английского языка.
volgograd.banbochka.ru
Изучение языка делает человека увереннее.
С помощью английского, можно учиться за границей без трудностей.
Также, изучение языка улучшает мышление.
Таким образом, умение говорить по-английски играет важную роль в саморазвитии каждого человека.
Английский язык сегодня считается важным умением для жителя современного мира.
Английский язык помогает находить общий язык с людьми со всего мира.
Без знания английского почти невозможно развиваться профессионально.
Многие компании предпочитают знание английского языка.
английский язык для взрослых
Изучение языка делает человека увереннее.
Благодаря английскому, можно учиться за границей без перевода.
Кроме того, изучение языка улучшает мышление.
Таким образом, знание английского языка играет важную роль в будущем каждого человека.
Английский язык сегодня считается важным навыком для современного человека.
Он помогает взаимодействовать с иностранцами.
Без владения языком сложно строить карьеру.
Работодатели оценивают специалистов с языковыми навыками.
bratsk.forum24.ru
Обучение английскому делает человека увереннее.
Благодаря английскому, можно учиться за границей без трудностей.
Также, овладение английским улучшает мышление.
Таким образом, знание английского языка является залогом в будущем каждого человека.
Английский язык сегодня считается важным инструментом для современного человека.
Английский язык позволяет находить общий язык с иностранцами.
Без знания английского почти невозможно строить карьеру.
Организации предпочитают сотрудников, владеющих английским.
https://domochozyayki.ru/poleznye-sovety/34223-vozrastnye-osobennosti-programmy-angliyskogo-dlya-detey-10-13-let/
Изучение языка открывает новые возможности.
Зная английский, можно путешествовать без ограничений.
Помимо этого, регулярная практика развивает память.
Таким образом, знание английского языка играет важную роль в саморазвитии каждого человека.
Английский язык сегодня считается незаменимым инструментом для современного человека.
Он позволяет находить общий язык с людьми со всего мира.
Не зная английский почти невозможно строить карьеру.
Организации оценивают знание английского языка.
уроки английского для детей
Изучение языка открывает новые возможности.
С помощью английского, можно путешествовать без ограничений.
Помимо этого, регулярная практика улучшает мышление.
Таким образом, знание английского языка становится ключом в саморазвитии каждого человека.
Английский сегодня считается незаменимым навыком для современного человека.
Он позволяет взаимодействовать с жителями разных стран.
Не зная английский трудно достигать успеха в работе.
Организации требуют сотрудников, владеющих английским.
http://ls.co-x.ru/2025/08/25/zahoteli-nauchitsya-angliyskomu-yazyku-obratites-k-professionalam.html
Регулярная практика английского открывает новые возможности.
Зная английский, можно читать оригинальные источники без ограничений.
Также, регулярная практика развивает память.
Таким образом, умение говорить по-английски является залогом в саморазвитии каждого человека.
Dating platforms for adults make it easier for individuals to find like-minded partners.
They are created for those who appreciate open communication.
Such platforms provide a comfortable space for getting to know others on the internet.
A lot of people turn to online dating to broaden their circle.
EroticVault
The main goal of such platforms is to help people who share similar interests.
Positive interaction on these platforms helps build trust.
Online communication formats make dating more diverse than ever before.
Ultimately, online platforms for adults help people feel connected regardless of busy schedules.
Английский язык сегодня считается необходимым умением для современного человека.
Он дает возможность находить общий язык с людьми со всего мира.
Не зная английский сложно развиваться профессионально.
Многие компании оценивают знание английского языка.
life.shoutwiki.com
Регулярная практика английского открывает новые возможности.
С помощью английского, можно читать оригинальные источники без перевода.
Также, регулярная практика улучшает мышление.
Таким образом, знание английского языка является залогом в успехе каждого человека.
Английский сегодня считается важным инструментом для жителя современного мира.
Он дает возможность взаимодействовать с жителями разных стран.
Не зная английский почти невозможно строить карьеру.
Многие компании оценивают сотрудников, владеющих английским.
корпоративное обучение английскому языку
Обучение английскому делает человека увереннее.
Благодаря английскому, можно путешествовать без трудностей.
Также, изучение языка развивает память.
Таким образом, владение английским становится ключом в будущем каждого человека.
Английский язык сегодня считается важным инструментом для современного человека.
Он дает возможность взаимодействовать с людьми со всего мира.
Не зная английский почти невозможно строить карьеру.
Многие компании требуют знание английского языка.
https://do-vgapo.ru/individualnye-onlayn-zanyatiya-po-angliyskomu-dlya-detey-effektivnyy-put-k-yazykovomu-masterstvu-v-ufirst.html
Обучение английскому делает человека увереннее.
Зная английский, можно путешествовать без ограничений.
Также, изучение языка развивает память.
Таким образом, знание английского языка играет важную роль в успехе каждого человека.
Знание английского языка сегодня считается незаменимым навыком для жителя современного мира.
Английский язык помогает находить общий язык с жителями разных стран.
Без владения языком почти невозможно развиваться профессионально.
Многие компании оценивают специалистов с языковыми навыками.
интенсивное изучение английского языка
Изучение языка делает человека увереннее.
С помощью английского, можно учиться за границей без ограничений.
Помимо этого, регулярная практика улучшает мышление.
Таким образом, умение говорить по-английски становится ключом в будущем каждого человека.
Получение второго гражданства за границей становится всё более востребованным среди граждан РФ.
Такой вариант даёт дополнительные перспективы для работы и бизнеса.
ВНЖ помогает беспрепятственно путешествовать и упрощать поездки.
Кроме того такой документ может повысить финансовую стабильность.
Гражданство за Инвестиции
Многие россияне рассматривают ПМЖ как способ расширения возможностей.
Имея ВНЖ или второй паспорт, человек расширить свои связи за рубежом.
Разные направления предлагают индивидуальные возможности получения вида на жительство.
Поэтому идея второго паспорта становится особенно актуальной для тех, кто ищет стабильность.
Продажа машины за короткий срок — это удобная услуга для тех, кто хочет продать транспорт без задержек.
Сервисы срочного выкупа проводят оценку машины максимально быстро.
После оценки клиент узнаёт реальную стоимость авто.
Главным достоинством срочного выкупа является оперативность оформления.
Не нужно встречаться с покупателями.
Компания сама занимаются оформлением документов.
Этот способ идеален для тех, кто ценит время.
Срочный выкуп авто — это оптимальный способ освободиться от ненужной машины.
https://forum.digiarena.zive.cz/memberlist.php?mode=viewprofile&u=219386
Casino Roulette: Spin for the Ultimate Thrill
Experience the timeless excitement of Casino Roulette, where every spin brings a chance to win big and feel the rush of luck. Try your hand at the wheel today at https://k8o.jp/ !
Competitive quizzing communities flourished behind Australian game shows. Many professional Chasers emerged from these scenes proving expertise through championship victories. https://australiangameshows.top/
Питомцы без забот — как выбрать и ухаживать за домашними любимцами. https://gratiavitae.ru/
Своевременная диагностика играет ключевую роль в лечебной практике.
Подобное обследование позволяет выявить заболевание на первых шагах развития.
Если вовремя проведено обследование, тем эффективнее подобрать подходящий лечебный план.
Многие пациенты недооценивают необходимость регулярных проверок, хотя это важный шаг к благополучию.
https://moscowfy.ru/medczentr-rosh-komfortnoe-i-kachestvennoe-lechenie-vedushhih-speczialistov/
Новые медицинские методы помогают получить объективные данные о состоянии организма.
Периодическая диагностика позволяют избежать критических ситуаций.
Для медиков раннее выявление болезни — это шанс улучшить прогноз.
Следовательно, своевременная диагностика является важным элементом заботы о здоровье.
скачать perplexity pro https://uniqueartworks.ru/perplexity-kupit.html
Learn how hormones, sleep, and food choices impact your metabolism and how to optimize them all. https://metabolicfreedom.top/ metabolic freedom audiobook
The RTP (Return to Player) is an essential factor for slot players, determining the percentage of wagers that will be returned as winnings over time. In the case of Gates of Olympus, the RTP stands at an appealing 96.5%, which is relatively standard for many online slots. Volatility, on the other hand, refers to the risk level, and this game has high volatility. While wins might be less frequent, the payouts are usually larger when they do occur. In comparison to other Pragmatic Play slots, Gates of Olympus has a balanced RTP and volatility combination, offering players a thrilling experience with the potential for significant rewards. According to our Gates of Olympus jackpot analysis, the slot has an RTP value of 96.5%. This is relatively decent, especially when considering that the slot is red hot. It wouldn’t come as a surprise if you bag the maximum win amount of 5,000x your stake on a single spin. The slot is extremely volatile which means that when a win does eventually land, it will certainly be worth all the wait.
https://www.joshhillbooks.com/2025/11/06/american-aviator-game-is-it-worth-playing-in-kenya/
Narakeet is an easy option to convert text to voice. Paste the text into our text-to-voice tool and just click the “Create Audio” button. Get started with our text to speech free online – no registration needed. – Product Explainer Videos AI text to video generator free creates a possibility to make concrete visuals for all types of text, from complex concepts to unimaginable descriptions, branching out to novels, comics, textbooks, podcasts, short serial stories, etc. Product to videoTransform your Amazon & Airbnb product listings into engaging videos ElevenLabs is widely regarded as one of the best text to speech platforms due to its ability to produce highly natural and expressive voices — and that’s why Kapwing’s Text to Speech Generator uses ElevenLabs’ API! Based on the true story of Jordan Belfort, from his rise to a wealthy stock-broker living the high life to his fall involving crime, corruption and the federal government.
In clinical practice, one often observes the unidirectional flow of medical instruction. A treatment plan is formulated and executed — this dynamic has been a cornerstone of modern medicine. This model, while efficient, overlooks critical variables.
The clinical picture, however, is frequently complicated by comorbidities. One begins to note a prevalence of treatment-resistant cases. These can range from persistent subclinical fatigue to cognitive disturbances. An analysis of individual metabolic and genetic factors often reveals a landscape of interactions that was not initially apparent.
This is the cornerstone of personalized medicine. The same molecular entity can be curative for one patient and merely palliative or even detrimental for another. Long-term health outcomes are shaped by these subtle, cumulative decisions.
Therefore, fostering a collaborative doctor-patient relationship is paramount. The informed patient is empowered to work synergistically with their healthcare provider. For those seeking to deepen their understanding of this complex interplay, we advise delving into the subject further. A prudent starting point for any individual would be to research and better understand tadacip 20 mg reviews.
This discussion is designed to be informative, but it is not a replacement for a consultation with a qualified healthcare provider. Always seek the advice of your physician or another qualified health professional with any questions you may have regarding a medical condition.
Осознанный подход к игре является значимым элементом безопасного досуга.
Она помогает избежать лишних рисков и сохранять баланс во время игрового процесса.
Многие люди понимают, что самоконтроль помогает сохранять позитивные эмоции без дискомфорта.
Соблюдение собственных границ позволяет регулировать активность.
https://blokov-casino.net/online-casino-martin/
Также, важно осознавать свои привычки и останавливаться вовремя.
Сервисы часто предлагают функции ограничения, которые помогают поддерживать здоровый подход.
Пользователи, которые придерживаются принципов ответственности, чаще поддерживают эмоциональный комфорт.
В итоге, ответственная игра остаётся важным правилом для всех.
Yay google is my world beater assisted me to find this outstanding web site! .
Download the Gates of Olympus 1000 app now and let the games begin! This website is using a security service to protect itself from online attacks. The action you just performed triggered the security solution. There are several actions that could trigger this block including submitting a certain word or phrase, a SQL command or malformed data. Existem diferentes ofertas nos melhores cassinos online do Brasil. Mesmo nos bônus sem depósito existem diferenças das quais você deve estar ciente. Alguns oferecem uma combinação de rodadas grátis e saldo de bônus após o registro. Abaixo explicamos cada um detalhadamente. This website is using a security service to protect itself from online attacks. The action you just performed triggered the security solution. There are several actions that could trigger this block including submitting a certain word or phrase, a SQL command or malformed data.
https://milhonferramentas.com/?p=33391
Eu fiquei impressionado com a quantidade de provedores de softwares que são parceiros da Luva Bet. Eu contei mais de 100 opções diferentes, incluindo PG Soft, Pragmatic Play e NetEnt. A bet do Luva de Pedreiro conta hoje com cerca de 2.000 jogos, com destaque para os mais de 1.200 games do tipo slots online e crash. Eu fiquei impressionado com a quantidade de provedores de softwares que são parceiros da Luva Bet. Eu contei mais de 100 opções diferentes, incluindo PG Soft, Pragmatic Play e NetEnt. Whether you’re a fan of the original Gates of Olympus or new to the world of Zeus, this app provides an authentic and thrilling slot experience. The intuitive interface makes it easy to spin the reels and chase those godly wins. This website is using a security service to protect itself from online attacks. The action you just performed triggered the security solution. There are several actions that could trigger this block including submitting a certain word or phrase, a SQL command or malformed data.
Une approche responsable du jeu est essentiel pour maintenir une expérience de jeu équilibrée.
Il permet de éviter les excès et de garder le contrôle tout en appréciant l’activité.
Un grand nombre de personnes comprennent que l’autocontrôle aide à prévenir les conséquences négatives.
Définir des règles personnelles permet de réguler son activité.
http://www.oraerp.com/thread-421-post-303172.html#pid303172
Il est également important de surveiller ses émotions et de s’accorder un arrêt.
Plusieurs services proposent des outils d’autocontrôle pour encourager un jeu sain.
Les personnes qui jouent consciemment parviennent souvent à maintenir une stabilité émotionnelle.
Finalement, le jeu responsable reste un élément indispensable pour un loisir équilibré.
Automat obsahuje několik skvělých bonusvoých funkcí, včetně free spinů a velmi populární funkce Buy Free Spins, díky které si koupíte roztočení zdarma a nemusíte čekat, až vám padnou scatter symboly. Chcete dobít bájný Olymp a ještě cestou vyhrát nějaké peníze? Zahrajte si populární automat Gates of Olympus a možná se vám to podaří. „Gates of Olympus Megaways“ se nezdá být uznávanou variantou výherního automatu Gates of Olympus vyvinutého Pragmatic Play. Originální slot je široce uznáván pro svou podmanivou grafiku a poutavou hratelnost. Přeneste se s námi do dávných dob, kdy antičtí bohové vládli Řecku. V dnešní recenzi se podíváme na známou klasiku od Pragmatic Play – Gates of Olympus. Jedná se o automat, který zná, každý hráč v online kasinech. Ať už jde o začátečníka nebo veterána. Pojďme s námi překročit brány Olympu a zjistit, jaké bonusy a výhry se za nimi skrývají. V této recenzi naleznete vše, co byste měli o tomto automatu vědět.
https://30000.com.tw/recenze-online-automatu-gates-of-olympus-od-pragmatic-play/
Prahran bingo Nevidíme žádný důvod, Porovnejte výplatní tabulku hry. V online casinu Apollo Games najdete sloty pocházející z dílen několika známých herních vývojářů. Určitě víte, že si v herní nabídce můžete libovolně filtrovat a to třeba právě podle výrobce. Nyní se podíváme na přehled TOP 5 nejhranějších her od jednotlivých vývojářů. Po nějaké době tu máme opět „našeho Matesa“ a jeho recenze. Automat jsme si radostí zahráli a můžeme potvrdit, že Gates of Olympus 1000 je epickou evolucí původní hry. Multiplikátory, které mohou dosáhnout 1 000×, dodávají neuvěřitelné vzrušení, zejména během Free Spins, kde se postupně sčítají a mohou vést k obřím výhrám.
Платформа EasyDrop считается востребованным сайтом для получения кейсов со скинами в CS2.
Многим пользователям нравится, что здесь простая навигация, позволяющий спокойно ориентироваться к работе платформы.
На ресурсе доступно широкий выбор наборов, что создаёт больше вариантов для выбора.
Создатели платформы регулярно пополняют коллекции, чтобы пользователи имели доступ к современным скинам.
easydrop лучшие кейсы
Многие отмечают, что EasyDrop удобен в использовании благодаря структурированным разделам.
Также ценится то, что платформа предоставляет разные варианты взаимодействия, повышающие общую динамику работы.
Тем не менее необходимо понимать, что любые действия на подобных платформах требуют осознанного использования.
В целом, EasyDrop воспринимается как онлайн-платформа для досуга, созданный для тех, кто интересуется коллекционными предметами в CS2.
Наблюдение за серверами является важной задачей для обеспечения надежности инфраструктуры.
Он позволяет выявлять неполадки на начальных этапах.
Своевременное обнаружение проблем позволяет избежать сбоев в работе.
Многие компании понимают, что регулярный мониторинг повышает надежность систем.
Современные инструменты позволяют автоматизировать процесс.
Своевременные уведомления помогают быстро реагировать и избегать сбоев.
Помимо этого, наблюдение повышает производительность серверов и экономит ресурсы.
Следовательно, регулярный мониторинг серверов — это основа для бесперебойной работы сервисов.
https://naphopibun.go.th/forum/suggestion-box/315265-v-bshch-u-v-s-v-d-s-bja-in-rn-v-p-sl-dn-vr-ja-d
Discount codes are unique combinations of letters and numbers that provide extra savings.
They are widely applied by brands to attract customers.
Such codes allow users to save more when making a purchase.
Many people appreciate promo codes because they help stretch the budget.
https://dosweeps.com/promotions/sweepshark-sign-up-bonus
Many stores share these codes through promotional campaigns.
Using them is usually easy and requires only adding the string during checkout.
Promo codes also help companies boost activity by offering limited-time rewards.
Overall, they serve as a useful option for anyone who wants to shop smarter.
Овладение английским считается ключевым навыком в современном мире.
Он позволяет общаться с людьми из других стран.
Многие специалисты понимают, что английский открывает новые возможности.
Овладение английским делает поездки комфортными и способствует межкультурному общению.
https://forum.battlecityalpha.xyz/thread-4584-post-40827.html#pid40827
Он также развивает когнитивные способности и укрепляет самостоятельность в различных ситуациях.
Учёба английского даёт доступ к информации в науке, технике и бизнесе.
Регулярное изучение помогает постоянно улучшать способности и оказывается полезным.
Следовательно, знание английского языка является важным фактором успеха в личной и профессиональной жизни.
Envision the intricate web of well-being, where experts frequently spot the strong influence of traditional advice on our lifestyle decisions.
Visualize your health journey as a predictable road, seldom branching off to explore uncharted territories that could lead to true transformation.
It wraps us in a comforting routine, yet prompts us to wonder about the hidden trade-offs involved.
Still, life itself thrives on boundless diversity in how our bodies respond and adapt.
Spanning from minor ebbs in energy to significant waves of change, this individuality is impossible to overlook.
Your body’s innate tempo influences how various elements integrate and interact within you.
As if gently unfolding a narrative etched in soft murmurs.
unveils the elegance inherent in paths tailored specifically to you.
Picture health as an expansive artwork, brushed with strokes that reflect your essence alone.
An element that harmonizes perfectly for one individual might encourage thoughtful adjustments in someone else.
Equilibriums naturally adjust as we listen closely and make refinements along the path.
Step boldly into your position as the creator of your own balanced existence.
Foster your exploration with a sense of awe and continuous revelation.
Strengthen your foundation with rich veins of knowledge and perspective.
Curious to uncover hidden gems of wisdom? Venture forth to learn about tadapox erfahrung
Fans von Automatenspielen bevorzugen Free Spins, die manchmal keine vorherige Geldeinzahlung erfordern. Wähle das Angebot, das am besten zu dir passt, um diese Vorteile zu genießen, wenn du anfängst zu spielen. Unser Team erforscht ständig den Gambling-Markt, um seriöse Online Casinos für deutsche Glücksspieler zu finden. Du kannst um echtes Geld spielen, noch bevor du echtes Geld auf das Casino-Konto transferiert hast. Auch das ist ein Grund, warum wir dir raten, ausschließlich in lizenzierten Online-Spielhallen zu spielen.
Während Freispiele ohne Einzahlung risikofrei sind, bieten Freispiele mit Einzahlung oft höhere Gewinne und bessere Bedingungen. Jetzt könnt ihr eure Freispiele an den angegebenen Spielautomaten genießen. Stöbert durch unsere Topliste der https://online-spielhallen.de/beste-online-casinos-deutschland-top-10-nov-2025-3/, die Freispiele anbieten. Genau deshalb haben wir für euch eine einfache Anleitung erstellt, mit der ihr eure Freispiele schnell und unkompliziert sichern könnt.
Colin Farrell spielt „Brendan Reilly“, einen früheren BeamtenGroßbritanniens, der sich selbst der Aristokratie zugeordnet hat. Packt es Colin Farrelldas Publikum mitzureißen oder kann der Streifen von 2025 mit dengroßen Denkmälern der Casino-Filmgeschichte nicht mithalten? Oft werden dieZuschauer mit einer Person konfrontiert, die entweder wie bei Ocean’sEleven den ganz großen Raub-Coup plant oder die selbst spielt undsich im Strudel der Sucht verliert. Zwischen einem großen Casino in Las Vegas undeiner Online-Spielbank gibt es allerdings immense Unterschiede unddas zeigt sich im Film. Mit Colin Farrell ist auch diesmal kein Unbekannter Hauptakteur zusehen, Tilda Swinton übernimmt die weibliche Hauptrolle und istgleichsam bekannt.
Obwohl man gemeinsam mit Rothstein das Gef�hl hat, um ein paar wichtige Lektionen des Lebens reicher geworden zu sein, bleibt die Frage nach dem Sinn. Casino zeigt eine Industrie unter Ratio�na�li�sie�rungs�zw�ngen, er zeigt, was sich unter den feinen Anz�gen und Smokings, die auch die Mafiosis tragen, verbirgt. An der Ober�fl�che ist der Mafiosi ein Rebell, irgendwie auch ein kleiner Robin Hood, und �berdies ein Fami�li�en�vater, der seinen Clan zusam�men�h�lt. Kaum eine zweite Insti�tu�tion zeigt die Schat�ten�seiten des Kapi�ta�lismus in �hnlicher Deut�lich�keit.
References:
https://online-spielhallen.de/casino-of-gold-bonus-spiele-anmeldung/
Im Nachhinein kann das Treffen in Warnemünde als Wendepunkt in der deutschen Online Casino Glücksspiel-Geschichte gesehen werden. Im Umkehrschluss heißt dies aber nicht, dass in der Vergangenheit das Online Casino spielen illegal war, ganz im Gegenteil. Um an legalen Glücksspielen teilzunehmen, müssen spezifische Anforderungen beachtet werden, um rechtliche Konsequenzen zu vermeiden.
Möchtest du deine Lieblingsspiele in den besten deutschen Online Casinos auch von unterwegs aus spielen? In den Konditionen des Casino Bonus ist genau festgelegt, wie Sie den Bonusbetrag vor der Auszahlung freispielen müssen. Als Willkommensbonus können Sie sich einen 100% Bonus auf bis zu 50 € sichern, um Ihre Lieblingsautomaten zu spielen. Wenn Sie online mit Ihrem eigenen Geld spielen, sollte es auf jeden Fall ein seriöses Casino sein. Es gibt zwei Möglichkeiten, Casino Spiele online zu spielen – im Demomodus oder um Echtgeld.
References:
https://online-spielhallen.de/vulkan-vegas-deutschland-test-angebote/
Oltre al cambio di tema, Pirots X introduce anche nuove dinamiche di gioco, abbandonando la meccanica di pagamento CollectR™ presente nella versione precedente. Se hai seguito le precedenti puntate della saga Pirots firmata ELK Studios, saprai che ogni capitolo ha offerto un salto tematico inaspettato. I quattro pappagalli protagonisti di questa storia atterrano sempre con gemme del colore corrispondente e si spostano per raccogliere le gemme adiacenti in qualsiasi direzione. Le gemme offrono premi in denaro istantanei a partire dal livello 1, ma possono essere potenziate a livelli superiori, offrendo rendimenti migliori. Tutti i simboli raccolti dai rulli, escluso il simbolo Bonus, possono attivare determinate funzioni e possono espandere la griglia fino a un massimo di 8×8. Quando non vi sono più vincite disponibili, i simboli “Bomb” raccolti da un volatile possono esplodere; l’esplosione fa espandere i rulli fino a ottenere una griglia di gioco 8×8 e cancella tutti i simboli presenti, eccezion fatta per i simboli “Feature”.
https://bmstrading.ca/gonzos-quest-slot-volatility-tutto-quello-che-devi-sapere/
Il sistema di gioco si basa su combinazioni a cluster e sull’intervento di funzioni speciali che amplificano le possibilità di vincita. Per comprendere meglio le probabilità di base, presentiamo una tabella semplificata che illustra i principali scenari di gioco. Ogni valore è indicativo e serve a mostrare il funzionamento generale della slot, in cui i simboli raccolti dai personaggi e i moltiplicatori globali giocano un ruolo centrale. L’esperienza completa offre anche la possibilità di accedere a funzioni bonus, come Free Drops e Super Bonus, fino a raggiungere l’obiettivo massimo, indicato come pirots x max win, che rappresenta la vincita più elevata ottenibile. Phone: +34 932 37 11 18 La versione Android di Pirots è compatibile con la maggior parte dei dispositivi, offrendo un’interfaccia reattiva e animazioni fluide. Il download diretto dal nostro sito consente di installare l’app senza passaggi complessi e garantisce l’accesso sicuro a tutte le funzioni di gioco. Con un semplice tocco è possibile entrare nel mondo di Pirots casino e partecipare a sessioni ovunque, sfruttando la stabilità e la velocità tipica dei sistemi Android.
Перевозка товаров по Минску играет значимую роль в развитии столицы.
Этот сектор поддерживает своевременную доставку продукции для компаний и частных клиентов.
Стабильная система доставки помогает избегать задержек и поддерживать стабильность бизнеса.
Многие предприятия Минска опираются на стабильные доставки, чтобы поддерживать производство.
Перевозка товаров Минск
Логистические службы используют надёжный автопарк, чтобы сохранять высокий уровень сервиса.
Регулярные грузоперевозки также обеспечивают снабжение в столице, создавая устойчивый поток товаров.
Для жителей города важна точность доставки, что делает качественные перевозки приоритетом.
В итоге, грузоперевозки в Минске остаются ключевым элементом инфраструктуры и играют значимую роль в повседневной жизни.
Jede Promotion ist darauf ausgerichtet, zusätzlichen Wert zu bieten, das Spielerlebnis zu verbessern und die Chancen auf Gewinne zu erhöhen. Zur Bereicherung des Spielerlebnisses bietet Vegadream zahlreiche Aktionen und Boni an. Der Live-Casino-Bereich steigert das Erlebnis noch weiter und bringt die Spannung echter Casinospiele mit professionellen Dealern und Live-Streaming direkt auf den Bildschirm. Die Spielerinnen und Spieler können sich in eine Vielzahl von Spielautomaten vertiefen, die von klassischen Drei-Walzen-Spielautomaten bis hin zu den neuesten Videospielautomaten mit innovativen Funktionen reichen. Ob Sie ein erfahrener Spieler sind oder das erste Mal die aufregende Welt der Online-Casinos betreten, Vegadream bietet ein spannendes Abenteuer voller Nervenkitzel, Unterhaltung und der Möglichkeit, große Gewinne zu erzielen.
Und Ihre dritte Einzahlung wird mit 120% bis zu 500 Euro plus 50 Freispielen für Book of Tribes belohnt. Bei der zweiten Einzahlung bekommen Sie dann weitere 150% bis zu 500 Euro an Bonusgeld sowie 30 Freispiele für Book of Fallen. Alle Sofortspiele aus dieser Kategorie können auch ohne den Einsatz von Echtgeld ausprobiert werden.
References:
https://online-spielhallen.de/beste-online-casinos-2025-empfehlungs-guide/
Outstanding post, you have pointed out some superb points, I as well believe this s a very good website.
Mindful play is essential for maintaining a safe approach to entertainment.
It helps players remain focused and prevents negative outcomes.
By managing time, individuals can enjoy gaming safely without overextending themselves.
Recognizing one’s habits encourages more thoughtful choices during gameplay.
Reliable platforms often promote useful tools that assist users in staying disciplined.
Maintaining moderation ensures that gaming remains a positive activity.
For many players, responsible play helps avoid fatigue while keeping the experience fun.
In the end, mindful habits supports long-term well-being and keeps gaming healthy.
jackpot sweeps casino
Slot online Gates of Olympus zalety ma tak zróżnicowane, że każdy entuzjasta hazardu powinien się z nimi zapoznać. Największą korzyścią z gry jest oczywiście dostęp do bonusów, free spinów i mnożnika wygranych. Na tym jednak nie koniec, ponieważ gra oferuje też: Wszystkie wygrane rozliczane są bezpośrednio po rundzie i zasilają saldo gracza. Automat oferuje wygrane rzędu 100,000,000 już od pierwszego zakręcenia. Aby znaleźć aplikację oferującą Gates of Olympus Dice Demo, możesz odwiedzić strony z recenzjami kasyn online lub sprawdzić oficjalne strony internetowe zaufanych kasyn. Zazwyczaj te strony zapewnią linki do pobrania lub skierują Cię do odpowiedniego sklepu z aplikacjami w celu instalacji. Mobilna wersja tej mitycznej gry slotowej przynosi wiele korzyści. Po pierwsze, telefon komórkowy Gates of Olympus zapewnia graczom możliwość wzięcia udziału w niebiańskiej podróży z dowolnego miejsca, uwalniając się od ograniczeń gier komputerowych. Przyjazny dla użytkownika interfejs w połączeniu ze zoptymalizowaną grafiką gwarantuje, że wrażenia z gry nie zostaną pogorszone na mniejszych ekranach. Dodatkowo powiadomienia o ofertach specjalnych, bonusach i aktualizacjach informują graczy na bieżąco, usprawniając ich podróż w grze.
https://goneshpurup.com/sugar-rush-slodki-swiat-wygranych-w-kasynie-online/
1 Mowa o portalu Pudelek.pl, który pod względem poczytności dominuje nad pozostałymi tego rodzaju witrynami (zob. artykul serwisy -plotkarskie -plotek -pl -party -pl -i -hotplota -mocno -w -gore -pu delek -pl -przyciaga -najbardziej -top -10). Please enter a valid web address Darmowe uciechy automaty w telefon umożliwiają cieszenie czujności spośród uciechy dosłownie stale oraz wszędzie. Statystyki wskazują, że obecnie zawodnicy pod każdą szerokością geograficzną tak samo wielokrotnie pełnią pod telefonach i tabletach, co na komputerach oraz laptopach. Dostawcy aplikacji kasynowego obecnie ongiś zauważyli ten styl. Ezoteryka i parapsychologia Brought out of the shadow The article discusses Adam Mickiewicz.Proza artystyczna: opowiadania, szkice, fragmenty. Prose artistique: contess, essais, fragments, which is a bilingual (French-Polish) endeavour in translation and editing – broadly speaking, one of historical and literary character. The book was edited by Joanna Pietrzak-Thébault in collaboration with whom Maria Prussak, Krzysztof Rutkowski and Jacek Wójcicki. Maria Prusak initiated the project and coordinated the proceedings of the team. Mickiewicz’s works in French received new translation and were edited anew.
This website is using a security service to protect itself from online attacks. The action you just performed triggered the security solution. There are several actions that could trigger this block including submitting a certain word or phrase, a SQL command or malformed data. Gates of LeoVegas 1000 od Pragmatic Play VOX Casino zapewnia doskonałą wersję mobilną serwisu, kompatybilną z systemami iOS i Android. Strona automatycznie dostosowuje się do ekranów smartfonów i tabletów, oferując identyczne wrażenia jak wersja desktopowa. At GamblersArea, you’re not spinning in the dark. We are your compass through the wild world of online slots. A guide curating the finest, fiercest, and most feature-packed slots the industry has to offer, that is. 18+ Slot Gates of Olympus w trybie demonstracyjnym.
https://jobs.lajobsportal.org/profiles/7421462-anthony-pitts
Nie musisz zawsze grać w produkty od dewelopera Pragmatic Play z komputera stacjonarnego, ponieważ deweloper zapewnia kompatybilność z urządzeniami mobilnymi. Oznacza to, że jeśli masz smartfon lub tablet, masz możliwość grania w gry tego twórcy, gdziekolwiek się znajdujesz. Gry Pragmatic Play są zaprojektowane w technologii HTML5, w tym także gry z krupierem na żywo, dzięki czemu można łatwo grać w gry kasynowe mobilne z telefonu lub tabletu. Jeśli rozważasz odwiedzenie kasyna Harrahs Northern California, oryginalna Latarka AnyTime jest lekka i służy jako dynamit produkt promocyjny. Jeśli dodasz dane karty, które oferują efekty video oraz parę intrygująco przemyślanych opcji bonusowych. Mimo, best elk studios casino slots aby nawet zbliżyć się do ogromnej liczby gier. Możesz zagrać w niego w dowolnym momencie, które są dostępne w pobranej wersji.
https://t.me/s/Beefcasino_officials
Грузоперевозки в Минске играет ключевую роль в функционировании города.
Этот сектор гарантирует своевременную доставку материалов для организаций и частных клиентов.
Надёжная логистика помогает сокращать время ожидания и поддерживать ритмичность бизнеса.
Многие предприятия Минска опираются на стабильные доставки, чтобы поддерживать производство.
perevozimgruz.by
Транспортные организации используют разные виды транспорта, чтобы улучшать обслуживание.
Регулярные грузоперевозки также способствуют развитию бизнеса в столице, создавая надёжную систему оборота.
Для клиентов важна оперативность доставки, что делает качественные перевозки приоритетом.
Таким образом, грузоперевозки в Минске остаются важным звеном экономики и поддерживают рабочий ритм столицы.
¿Sientes pánico ante la idea de que termine la relación? https://lasmujeresqueamandemasiadopdf.cyou/ las mujeres que aman demasiado portada libro
Unlock the adventure that everyone is recommending. The Project Hail Mary PDF is the best way to read this bestseller digitally. You will be captivated by the science, the danger, and the humor. Get the ebook today and see why it is a classic in the making. https://projecthailmarypdf.top/ project hail mary where to watch
Awsome website! I am loving it!! Will be back later to read some more. I am taking your feeds also
Быстрый выкуп машин пользуется спросом среди владельцев транспортных средств.
Она позволяет оперативно реализовать машину без лишних хлопот.
Процесс оформления обычно занимает минимум времени.
Владельцам не нужно тратить время на показы.
Специализированные сервисы часто работают с разными машинами.
Это особенно актуально в ситуациях, когда деньги нужны срочно.
Определение стоимости проводится прозрачно, что позволяет сразу понять условия.
В итоге, срочный выкуп авто является удобным вариантом для быстрой продажи автомобиля.
https://www.democracyforums.com/memberlist.php?mode=viewprofile&u=6775
Модель типа «раздеватор» — это алгоритм искусственного интеллекта, которая анализирует изображения.
Она опирается на обученные модели для генерации альтернативных визуальных вариантов.
Работа таких систем основана на анализе контуров.
Подобные нейросети часто обсуждаются в контексте развития ИИ.
нейросеть раздевает людей по фото
При этом важно учитывать моральные аспекты и права человека.
Применение подобных решений требует ответственного подхода.
Многие эксперты подчёркивают, что важно соблюдать нормы и правила.
В целом, нейросеть-раздеватор является частью современного технологического ландшафта, который вызывает дискуссии.
Нижний Новгород является крупным городом в Приволжском регионе.
Он расположен на слиянии Волги и Оки, что повлияло на формирование города.
Этот город привлекает культурным наследием.
Облик Нижнего Новгорода сочетает исторические здания и новые районы.
Нижний Новгород события и свежие новости
Здесь успешно формируется деловая среда.
Ритм Нижнего Новгорода отличается активностью и широким выбором мероприятий.
Нижний Новгород также является важным транспортным узлом.
В целом, Нижний Новгород считается комфортным местом для жизни для жителей и гостей.
Модель типа «раздеватор» — это алгоритм искусственного интеллекта, которая обрабатывает визуальные данные.
Она использует методы машинного обучения для изменения внешнего вида на снимках.
Работа таких систем основана на выявлении визуальных особенностей.
Подобные нейросети часто обсуждаются в контексте современных цифровых технологий.
ии который делает фото голык
При этом важно учитывать границы допустимого и права человека.
Применение подобных решений требует ответственного подхода.
Многие эксперты подчёркивают, что ИИ должен применяться законно.
Таким образом, нейросеть-раздеватор является частью современного технологического ландшафта, который нуждается в внимательном отношении.
If you love stories about protective males and fierce females, this is for you. The A Court of Thorns and Roses PDF captures these dynamics perfectly. Read along as Feyre learns that the fae are not exactly the monsters she was taught to fear. https://acourtofthornsandrosespdf.top/ A Court Of Thorns And Roses Summary
A unique magic system based on dragon power. Read the Fourth Wing PDF to understand the mechanics. It is consistent and well-thought-out. https://fourthwingpdf.top/ Fourth Wing Pdf Book
Iron Flame burns bright for fans! Rebecca Yarros’ sequel sparkles with action and emotion. PDF free at ironflamepdf.top – dive in! https://ironflamepdf.top/ What Chapter Is The Throne Scene In Iron Flame
Discover why this fantasy series has broken sales records repeatedly. https://heiroffirepdf.top/ Heir Of Fire Pdf Online Free
Sunrise on the Reaping PDF uncovers the truth behind one of literature’s most fascinating characters. Suzanne Collins crafts this powerful prequel about young Haymitch facing the fiftieth Games. Witness his transformation from hopeful to broken. Free instant download with no registration needed. https://sunriseonthereapingpdf.top/ Sunrise On The Reaping Pdf Download
Hey there! I’ve been following your website for a long time now and finally got the bravery to go ahead and give you a shout out from Lubbock Texas! Just wanted to say keep up the excellent work!
Explore the delicate balance between light and dark magic. The An Arcane Inheritance PDF offers a front-row seat to this conflict. This electronic book is easy to navigate and read. Download it today to experience a story that redefines the genre of urban fantasy. https://anarcaneinheritancepdf.top/ An Arcane Inheritance Pdf English
Get the In Your Dreams PDF and see for yourself. The quality of the digital text, the ease of navigation, and the portability make it a winner for readers everywhere. https://inyourdreamspdf.top/ In Your Dreams Pdf Drive
This book makes you scream, and you can love the PDF. It is a passion. The digital edition is heart. warm and fuzzy. https://youcanscreampdf.top/ You Can Scream Full Story Download
Searching for high-quality ebooks can sometimes feel like a treasure hunt. When you stumble upon a true archive of romance, it feels like hitting the jackpot. I appreciate having access to PDF versions because they maintain the original formatting of the book, providing a superior reading experience on my tablet. https://anarchiveofromancepdf.top/ Read An Archive Of Romance Full Novel
If you need a PDF that makes you scream, you can exit this. It is a bye. The story is leave. go and gone. https://youcanscreampdf.top/ You Can Scream Free Download
You can find a western that makes you scream. This PDF is a wild ride. It is a gritty and exciting story. The digital format brings the old west to your modern device. Saddle up and start reading today. https://youcanscreampdf.top/ Rebecca Zanetti Latest Book Pdf
For those who love to write reviews, access to books is key. An archive of romance provides plenty of material. I download PDF copies to review on my social media, helping other readers find their next great read among the vast selection available. https://anarchiveofromancepdf.top/ An Archive Of Romance Digital Copy
I appreciate the sheer quantity of content. An archive of romance has more books than I can read in a lifetime. The endless list of PDF titles is both daunting and exciting, promising that I will never, ever be bored again. https://anarchiveofromancepdf.top/ An Archive Of Romance Chapters Pdf
Die Bonus-Buy-Funktion in Sugar Rush 1000 bietet sofortigen Zugang zur Freispielrunde mit dem 100-fachen des Einsatzes oder zu den Super-Freispielen mit dem 500-fachen, bei denen die Multiplikatoren bereits auf dem Raster liegen, allerdings mit einem niedrigeren RTP von 96,52 %. Dieses Slot-Spiel bietet eine Reihe von Symbolen, die in zwei Gruppen unterteilt sind. Es gibt drei Arten von Gummibärchen, bei denen eine Kombination von mindestens fünf Symbolen einen Gewinn von 0,2 bis 0,3 des Einsatzes bringt. Zusätzlich gibt es vier Symbole, die als wertvoller angesehen werden, und die gleiche Anzahl von diesen in einer Kombination erhöht die Auszahlung auf 0,4 und 1 des Einsatzes. Für die größte Kombination im Spiel, mit 15 oder mehr identischen Symbolen, steigen die Belohnungen. Spieler können das 20- bis 30-fache ihres Einsatzes verdienen, wenn sie Gummibärchen kombinieren, und für die verschiedenen Bonbons reichen die Erträge von 40 bis zu 150-mal den Einsatz in Sugar Rush 1000.
https://docs.lagonette.org/s/Syplgvr9s
In our guide on the best RTP slots, we will take you through the best RTP slot games at the best online casinos. If you are interested in iGaming and want to start playing online casino games, then read on and find out all you need to know about the best RTP slots. Besonders schätze ich, dass man bei den Stake Originals wie Dice oder Crash über das Smartphone dieselbe Performance bekommt wie am Desktop. Wer also jederzeit Einsätze platzieren möchte – ob in der Bahn, im Café oder bequem zu Hause –, wird mit dieser plattform zufrieden sein. Eine native App installieren Sie am besten direkt via QR-Code oder Link auf der Website: für iOS im App Store, für Android aus einer externen Quelle. So sind alle Features sofort verfügbar, inklusive Rakeback, VIP-Funktionen und promotion-Sektion.
I find that reading helps me sleep. A gentle story from an archive of romance is my sleeping pill. I read a low-stakes, sweet PDF novel in bed, and it helps quiet my racing thoughts, allowing me to drift off into a peaceful slumber. https://anarchiveofromancepdf.top/ Read An Archive Of Romance Online Free
Dit product is niet beschikbaar. Kies een andere combinatie. Algemene voorwaarden | Veiligheid & Privacy | KvK: 52288579 | BTW: NL002160084B57 De Visconti vulpen heeft een 14 kt gouden penpunt, is verkrijgbaar in verschillende lijndiktes en maakt gebruik van het Power Filler vulmechanisme. Scheepjes Maxi Sweet Treat, Maxi Sugar Rush en Maxi zijn identieke garens qua samenstelling, maar ze verschillen in looplengte. De aanbevolen naalddikte voor deze garens is 1.25-1.50 mm, wat ideaal is voor fijne haak- en breiprojecten. Sugar Rush heeft ook een spannende progressieve jackpot, waar je kans op kunt maken door het Sugar Rush-symbool te scoren. Draai vijf van deze symbolen op een actieve winlijn en je wint de jackpot. Download voor iPhone, iPad of Android (gratis) Een schrijfervaring die het avontuur en de sensatie van creatieve ontdekkingen weergeeft met een nieuwe, geheel in eigen huis geproduceerde 14kt gouden penpunt. De klassieke brugvormige clip, een onderscheidend kenmerk van onze schrijfinstrumenten, toont het Visconti lasergegraveerde logo.
https://www.play56.net/home.php?mod=space&uid=5811241
Sugar Rush slot oyununu çevrimiçi olarak oynamak için bir tarayıcınızın olması yeterlidir. Sugar Rush slot machine oyununu indirmek için arama motorlarında arama yapabilirsiniz. Fakat, oyun oynanabilecek sitelerin yasal olup olmadığını teyit etmek önemlidir. Bekijk: BABYMONSTER deelt Rora, Chiquita, Haram en Asa’s cover van BLACKPINK’s ‘STAY’ Critics’ Choice Awards 2020 Een tweede stap in een goedwerkende flow is mensen laten overwegen om een product in jouw webshop te kopen. Voor Goldfish werken we hier met de campagnedoelstelling ‘catalogusverkopen’ zodat de kleding automatisch wordt ingeladen in onze carrouseladvertenties. Met een aantrekkelijke copy proberen we in te spelen op de actualiteit, zoals de solden, een hittegolf, enzovoort. Deze advertenties worden alleen getoond aan warme doelgroepen; zoals engagors van de Facebook- of Instagrampagina, maar ook previous buyers.
Experience the magic of a romance that feels real. The Love in Plane Sight PDF is available for download. This novel is a beautiful portrayal of love in the modern world. Secure your digital file today and enjoy the story. https://loveinplanesightpdf.site/ Love In Plane Sight Saga
The Bluebird Gold PDF is your essential guide to the gold industry. It provides a detailed overview of market conditions and strategic advice for investors. Download this report now to sharpen your financial skills and secure your investment future. https://bluebirdgoldpdf.site/ Bluebird Gold Mystery Elements
Dressing stylishly is important for building confidence.
It helps highlight individuality and boost self-esteem.
A neat outfit affects social perception.
In daily life, clothing can increase self-assurance.
https://telegra.ph/Etro-12-25
Thoughtful clothing choices support professional encounters.
It is important to consider personal preferences and appropriate setting.
Current trends allow people to explore new ideas.
Ultimately, dressing stylishly completes your personal image.
Students and researchers often look for accessible formats for their studies, and the chosen family pdf provides an excellent resource for analyzing modern social structures and the evolving definition of kinship in the twenty-first century without the hassle of physical library loans. https://chosenfamilypdf.site/ Chosen Family Magnet Link
Expand your horizons with a novel that travels with you. The Graceless Heart PDF is global. It is a story that transcends borders, available in a format that you can download and read anywhere in the world. https://gracelessheartpdf.site/ Graceless Heart Google Drive
Feel the tension rise as the characters realize they are trapped in a horror movie logic. It is a brilliant deconstruction of the genre. The Bury Your Gays PDF is a must-have for students of film and literature who want to see theory put into practice. https://buryyourgayschucktinglepdf.site/ Bury Your Gays Tingle
Dive into a world where politics and love collide. The Boyfriend Candidate PDF is the best way to enjoy this story. It is available for instant access on any device. Download the ebook today and follow the characters on their journey to a happy ending. https://theboyfriendcandidatepdf.site/ The Boyfriend Candidate Pdf Free
perplexity premium https://uniqueartworks.ru/perplexity-kupit.html
La teoría de Let Them es la llave de la serenidad. Consigue el texto en español y lee la versión completa. No busques la llave fuera, está en tu capacidad de permitir; úsala para abrir la puerta a una vida donde el estrés es la excepción y la paz es la norma. https://lateorialetthem.top/ Teoria Let Them Mel Robbins Pdf
La verdadera revolución comienza cuando te amas a ti misma. Este libro electrónico es tu manual de instrucciones. Descubre por qué has tolerado lo intolerable y cómo dejar de hacerlo. Es el momento de descargar sabiduría y aplicarla a tu corazón. https://lasmujeresqueamandemasiadopdf.cyou/ Las Mujeres Que Aman Demasiado Pdd
Forget about quick fixes and focus on long-term metabolic health. This comprehensive resource is a game-changer for many. When you download the metabolic freedom pdf, you get access to a blueprint that helps you restore balance and burn fat naturally and effectively. https://metabolicfreedom.top/ Metabolic Freedom Pdf Free Download
Best Iphone 17 Pro Max Cases For Protection Iphone 17 Pro Price 2025 Msrp What Is The Price For Iphone 17 Pro Iphone 17 Pro Max Weight Grams Apple Iphone 17 Launch Date Rumors 2025 Iphone 17 Pro Max Release Date Uk Availability Apple Iphone 17 Colors Announced
If diets failed, try a metabolic reset. This book has answers. The metabolic freedom pdf outlines a method to restore your rate. https://metabolicfreedom.top/ Metabolic Freedom Sign In
Don’t let the Shield of Sparrows fly away; catch it in PDF. This digital file is yours to keep forever once downloaded. Build a library that lasts a lifetime with this permanent addition. https://shieldofsparrowspdf.site/ Download Shield Of Sparrows Free
Secure a copy of this influential critique on modern training methods. The fake skating pdf challenges outdated practices and suggests new, evidence-based approaches to developing talent and skill. https://fakeskatingpdf.site/ Fake Skating Lynn Painter Wattpad
Experience the benefits of the Charlie Method firsthand by exploring this detailed PDF. It contains in-depth explanations and practical examples to help you learn quickly. This guide is a must-have for anyone looking to optimize their strategies. Get the insights you need to succeed by accessing the file right now. https://thecharliemethodpdf.site/ The Charlie Method Free Download Link
Быть в курсе событий необходимо в современном мире.
Это помогает лучше ориентироваться и реагировать своевременно.
Оперативные новости позволяют планировать действия.
http://divisionmidway.org/jobs/author/wixafaf511/
Информированность способствует формированию собственной позиции.
В профессиональной сфере это даёт возможность оставаться конкурентоспособным.
В итоге, умение быть в курсе событий повышает качество жизни.
Стильная одежда играет важную роль в самовыражении.
Она помогает подчеркнуть индивидуальность и выглядеть гармонично.
Грамотно подобранный образ создаёт впечатление окружающих.
В повседневной жизни одежда может повышать самооценку.
https://telegra.ph/Loro-Piana-12-25
Хорошо подобранная одежда облегчает социальные контакты.
При выборе одежды важно учитывать собственный вкус и обстановку.
Современные тенденции дают возможность находить новые решения.
Таким образом, умение стильно одеваться делает образ завершённым.
Découvrez la genèse d’une vocation littéraire dans ce récit émouvant. Le livre à télécharger est une source d’inspiration. Laissez-vous guider par les mots de Maryse Condé dans ce voyage au cœur de sa mémoire, où chaque souvenir est une émotion retrouvée. https://lecoeurarireetapleurerpdf.site/ Le Cœur À Rire Et À Pleurer Texte Intégral
Un livre qui explore la mémoire avec une grande délicatesse. Le téléchargement est simple pour une lecture immédiate. Plongez dans l’univers de Maryse Condé et laissez-vous toucher par la beauté de ce témoignage qui traverse le temps et les frontières. https://lecoeurarireetapleurerpdf.site/ Le Cœur À Rire Et À Pleurer Résumé Court
Machen Sie den entscheidenden Schritt zu besseren Deutschkenntnissen. Unsere PDF-Sammlung hilft. Werden Sie fließend, indem Sie jetzt aktiv werden und lernen. https://becomingfluentingermanpdf.site/ German Conjunctions Pdf
Der wohl wichtigste deutsche Beitrag zur Weltliteratur des 20. Jahrhunderts. Sichern Sie sich Im Westen nichts Neues als PDF. Genießen Sie die Vorteile des digitalen Lesens und lassen Sie sich von der kraftvollen Sprache Remarques in eine vergangene, aber mahnende Epoche entführen. https://imwestennichtsneuespdf.site/ Welche Oscars Hat Im Westen Nichts Neues
Die Brüder Grimm haben Märchen aus verschiedenen Dialekten ins Hochdeutsche übertragen. Dennoch blitzt der Ursprung oft durch. Sprachinteressierte können in einer Grimms Märchen PDF diese sprachlichen Nuancen aufspüren und analysieren. https://grimmsmarchenpdf.site/ Brothers Grimm Fairy Tales Pdf
Die Charaktere sind oft einfach gestrickt, aber gerade das macht sie so universell. Jeder kann sich identifizieren. Finden Sie Ihre Rolle in den Geschichten einer Grimms Märchen PDF und erleben Sie die Abenteuer hautnah. https://grimmsmarchenpdf.site/ Grimms Märchen Münzen Wert
Ein Roman, der die Schrecken des Krieges fühlbar macht. Im Westen nichts Neues als PDF ist harte, aber notwendige Lektüre. Laden Sie das Buch und stellen Sie sich der Geschichte, damit sie sich nicht wiederholt. https://imwestennichtsneuespdf.site/ All Quiet On The Western Front Free Access
Es gibt viele Wege, eine Sprache zu lernen, aber strukturierte Unterlagen sind der Schlüssel zum Erfolg. Unsere PDF-Ressourcen bieten Ihnen einen klaren Fahrplan zur Sprachbeherrschung. Verwandeln Sie Ihr Ziel, fließend Deutsch zu können, in einen konkreten Plan mit messbaren Ergebnissen. https://becomingfluentingermanpdf.site/ Daily German Practice Pdf
Ein Paradies für Schleckermäuler ist ein Dessert-Café in Berlin Guide als PDF, der den Fokus auf die süßen Begleiter legt und dir zeigt, wo es die besten Macarons, Eclairs oder Pralinen zum Kaffee gibt. https://cafeinberlinpdf.site/ Cafe In Berlin Ebook Free
Egal ob du nur auf der Durchreise bist oder hier wohnst, die Kaffeekarte von Berlin ist riesig, und ein umfassendes PDF-Dokument hilft dir, diese Landschaft zu navigieren und genau das Café in Berlin zu finden, das in diesem Moment zu deinen Wünschen passt. https://cafeinberlinpdf.site/ Cafe In Berlin Epub
The In Your Dreams PDF is the choice of the future. As libraries go digital, having this file ensures you are keeping up with the times while enjoying a timeless piece of literature. https://inyourdreamspdf.top/ In Your Dreams Paperback Pdf
You can read a saga that makes you scream. This PDF is big. It is a world. The digital format is vast. open and wide. https://youcanscreampdf.top/ You Can Scream Text Format
For those who love to annotate their books, digital formats offer new possibilities. With a PDF from an archive of romance, I can highlight text and add notes without damaging a physical page. It is the perfect blend of active reading and preserving the integrity of the book. https://anarchiveofromancepdf.top/ Archive Of Romance Pdf Free
Saved as a favorite, I like your website!
The wait is finally over for fans of intense drama. Born of Trouble has arrived in a high-quality pdf format. Explore the depths of human emotion and the chaos of a life lived on the edge. Secure your copy today and join the community of dedicated readers worldwide. https://bornoftroublepdf.site/ Free Pdf Book Finder
Having read this I thought it was very enlightening. I appreciate you spending some time and energy to put this informative article together. I once again find myself personally spending a significant amount of time both reading and posting comments. But so what, it was still worthwhile!
Deutsche Klassiker: Besonders populär sind die Spiele von Herstellern, die Spieler aus landbasierten Spielotheken kennen und schätzen. Dazu zählen Merkur (z.B. Eye of Horus, Blazing Star, Fruitinator), Novoline (Book of Ra, Lucky Lady’s Charm, Sizzling Hot) und Gamomat (Ramses Book, Roman Legion, La Dolce Vita). Haben Sie Probleme mit Gates of Olympus? Gates of Olympus Dice shines as a stellar example of Pragmatic Play’s craftsmanship, blending engaging gameplay with rich features. The game’s Tumble Feature, combined with dynamic multipliers and the Free Spins round, elevates the excitement, offering players numerous ways to win. The Ante Bet and Bonus Buy options further enhance the strategic depth, making it a hit for those seeking control over their game experience. Die Transaktionen sind gebührenfrei. Die Gutschrift der Einzahlung erfolgt auf deinem Spielerkonto sofort.
https://bondagezog.com/bgaming-plinko-einblicke-in-plinko-lines-erfahrungen/
The poll also assessed voter satisfaction with Members of Parliament (MPs), revealing that 35% of respondents rated their MPs’ performance as average. Only 22% considered their MPs’ performance as very good or good, while 23% deemed it poor or very poor. Additionally, 11% rated their MPs as excellent, with 10% withholding their opinion. Stop by my web site Sportwetten Glücksspiel österreich 3Durch Öffnen der Leseprobe willigen Sie ein, dass Daten an den Anbieter der Leseprobe übermittelt werden. Pragmatic Play Slots is a collection of high-RTP, mobile-optimized video slots featuring cluster pays, tumbling reels, and bonus buy options. Titles include Gates of Olympus, Sweet Bonanza, and Big Bass Bonanza, known for volatility and max wins up to 25,000x. Direkter Einstieg in die Software-Module und weitere Videos.
Сфера недропользования — это комплекс работ, связанный с освоением природных ресурсов.
Оно включает добычу природных ресурсов и их дальнейшую переработку.
Недропользование регулируется установленными правилами, направленными на охрану окружающей среды.
Ответственное ведение работ в недропользовании обеспечивает устойчивое развитие.
оэрн
https://rijbewijskopenc.com
https://comprarcarnetdeconducira.com
http://kupprawojazdyb.com
http://kupprawojazdyb.com
Thanks for this helpful post. The information shared here is clear and useful. Keep updating
Hi to every , since I am truly eager of reading this website’s post to be updated on a regular basis. It includes fastidious data.
Чтение СМИ является необходимым в современном обществе.
Оно помогает быть в курсе событий и разбираться в текущих процессах.
Оперативная информация позволяют оценивать события.
Чтение СМИ способствует расширению кругозора.
https://telegra.ph/Omsk-12-25-2
Несколько точек зрения помогают анализировать информацию.
В профессиональной сфере СМИ дают возможность следить за тенденциями.
Регулярное изучение материалов формирует навыки анализа.
В целом, чтение СМИ поддерживает осведомлённость.
Dressing stylishly is important for creating a positive impression.
A thoughtful appearance helps highlight individuality.
Well-chosen outfits can improve self-esteem.
In everyday life, appearance often influences how others perceive you.
https://telegra.ph/Gucci-01-12-11
Balanced style choices make professional interactions smoother.
It is important to consider one’s own comfort as well as the occasion.
Modern styles give people the chance to refresh their image.
Ultimately, dressing stylishly helps people feel confident.
Nå har vi snakket ferdig om de problematiske sidene ved pengespill, og kan konsentrere oss om selve spillingen. I Gates of Olympus er det alltid 20 gevinstlinjer aktivert, men du kan selv justere innsatsnivået pr. linje og myntverdien. Førstevne varierer på en skala fra 1 til 10, mens myntverdien kan variere fra 1 krone til 5 kroner. Dette betyr at den laveste og den høyeste innsatsen er på henholdsvis 2 og 1000 kroner. Dette gjør at Gates of Olympus er en egnet automat for alle spillertyper, fra forsiktige nybegynnere til de som tenner sine sigarer med tusenlapper og alle derimellom. Den mytiske spilltittelen er en Pragmatic Play-opprettelse med høy spredning med en retur til spilleren på 96,50%. Det spilles ut i et 6×5-format med en vinn-alle-veier innsatslinje. Innsatsene varierer fra 0,20 til 100 per spinn.
https://chaihouse.menuqtr.com/index.php/2026/01/09/gates-of-olympus-en-grundig-anmeldelse-for-norske-spillere/
Vi ser nærmere på funksjonene, bonusrundene, gevinstpotensialet og mobilversjonen, og deler våre erfaringer med Gates of Olympus. Du får tips om beste strategi for å vinne på Gates of Olympus, hvor du kan spille Gates of Olympus helt gratis eller med ekte penger, og hvor du finner de beste bonusene. Før du spinner hjulene, bør du lese denne omtalen så du har det beste utgangspunktet. Hvem eier JohnVegas Casino? Én noe uvanlig faktor med kryptovaluta, er at hver enkelt betaling kommer med et tilknyttet gebyr – dette kalles ofte for «gas fees», eller «bensinpenger», og midlene går til datamaskiner servere som behandler transaksjonen. Følgende tall gjelder for ulike mynter; Mustang Gold er inspirert av det ville vesten. Det hele foregår i en vakker dal ved solnedgang, og på hjulene dukker det opp både cowboyer og villhester. Les mer om denne fartsfylte spilleautomaten fra Pragmatic Play, og kom deg opp på hesteryggen hos Big Boost.
Санкт-Петербург является крупным культурным центром России.
Город расположен на северо-западе страны и обладает богатым прошлым.
Архитектура Петербурга сочетает классические постройки и новые архитектурные решения.
Этот город славится культурными пространствами и богатой культурной жизнью.
Городские набережные создают уникальный характер.
Путешественники приезжают сюда круглый год, чтобы познакомиться с культурой.
Санкт-Петербург также является крупным транспортным узлом.
Таким образом, Санкт-Петербург считается особенным местом.
https://spacehey.com/profile?id=4387853
Продуманный образ является значимым фактором в формировании первого впечатления.
Одежда помогает подчеркнуть индивидуальность.
Гармоничный стиль повышает уверенность.
В повседневной жизни внешний вид часто определяет отношение окружающих.
https://www.tumblr.com/sneakerizer/779162701885784064/jil-sander-%D0%BA%D0%B0%D0%BA-%D0%BF%D0%BB%D0%B0%D1%82%D1%8C%D0%B5-%D0%BC%D0%BE%D0%B6%D0%B5%D1%82-%D0%B1%D1%8B%D1%82%D1%8C-%D1%82%D0%B8%D1%88%D0%B8%D0%BD%D0%BE%D0%B9-%D0%BA%D0%BE%D1%82%D0%BE%D1%80%D0%B0%D1%8F
Грамотно составленные образы упрощают социальное взаимодействие.
При выборе стиля важно учитывать индивидуальные особенности и уместность ситуации.
Мода дают возможность находить новые решения.
В итоге, умение стильно одеваться помогает чувствовать себя увереннее.
Понятие гедонизма — это мировоззренческий подход, которое выдвигает наслаждение в центр человеческой жизни.
Согласно этому взгляду, стремление к удовольствию считается естественной целью существования.
Гедонизм не всегда подразумевает излишество.
Во многих трактовках он предполагает баланс и ответственное отношение.
https://www.tumblr.com/sneakerizer/803905934927740928/c%C3%A9line-%D0%BB%D0%B0%D0%BA%D0%BE%D0%BD%D0%B8%D1%87%D0%BD%D0%B0%D1%8F-%D1%80%D0%BE%D1%81%D0%BA%D0%BE%D1%88%D1%8C-%D0%B8-%D1%82%D0%B8%D1%85%D0%B0%D1%8F-%D0%B4%D0%B5%D1%80%D0%B7%D0%BE%D1%81%D1%82%D1%8C
Современное понимание гедонизма часто акцентирует внимание на качестве жизни.
При этом важную роль играет сочетание между удовольствиями и реальными возможностями.
Гедонистический подход может поддерживать психологическое равновесие.
В итоге, гедонизм рассматривается как философская перспектива, а не как безусловное потакание желаниям.
Dressing stylishly is essential for self-expression.
A thoughtful appearance helps show personal taste.
A neat look can improve self-esteem.
In everyday life, appearance often influences how others perceive you.
https://graph.org/Uniqlo-01-12
Carefully selected clothing make communication easier.
It is important to consider one’s own comfort as well as the situation.
Fashion trends give people the chance to discover new ideas.
In conclusion, dressing stylishly positively affects perception.
A handbag is an important accessory in everyday life.
It combines functionality with style.
A good bag helps keep belongings in order.
At the same time, it can add balance to an appearance.
https://naijamatta.com/read-blog/39329
Various styles allow people to express personal taste.
A carefully selected bag often reflects personal preferences.
High-quality materials and design contribute to long-term use.
In conclusion, a bag remains a valuable element of a modern wardrobe.
Модно одеваться необходимо, потому что внешний вид задаёт образ.
Одежда помогает выразить индивидуальность.
Стильный образ добавляет уверенности и положительно влияет на настроении.
Модные вещи делают человека современным.
https://orlandomagicclub.com/read-blog/6140
В деловой и социальной среде внешний вид играет важную роль.
Мода позволяет соответствовать обстановке.
Кроме того, стильная одежда помогает выглядеть гармонично.
В итоге, умение модно одеваться становится важной частью самовыражения.
Продуманный внешний вид является значимым фактором в создании образа.
Она помогает выразить характер и чувствовать себя увереннее.
Аккуратный внешний вид формирует мнение окружающих.
В повседневной жизни одежда может придавать уверенность.
https://telegra.ph/Gucci-01-12-8
Стильный образ облегчает социальные взаимодействия.
При выборе вещей важно учитывать личные предпочтения и контекст.
Современные тенденции дают возможность находить новые решения.
В итоге, умение стильно одеваться помогает чувствовать себя увереннее.
Classic mechanical watches will always stay fashionable despite the growth of modern electronics.
They represent fine engineering built on precision.
Unlike electronic alternatives, mechanical watches rely on mechanical precision.
Watch enthusiasts value them for their history.
https://pbase.com/279silver/image/175482672
High-quality mechanical watches are often made using carefully selected components.
Their classic aesthetics allows them to remain stylish.
Beyond telling time, these watches serve as expressions of personal style.
Ultimately, mechanical watches continue to maintain their iconic status.
Умение стильно одеваться играет важную роль в формировании впечатления.
Она помогает передать личный стиль и чувствовать себя увереннее.
Аккуратный внешний вид формирует мнение окружающих.
В повседневной жизни одежда может помогать собранности.
https://telegra.ph/Versace-01-12-3
Хорошо подобранная одежда облегчает деловые контакты.
При выборе вещей важно учитывать личные предпочтения и контекст.
Мода дают возможность находить новые решения.
Таким образом, умение стильно одеваться помогает чувствовать себя увереннее.
Athletic shoes have become extremely popular in recent years due to their comfort.
They blend practicality with stylish looks.
Many people choose sneakers because they are easy to wear every day.
Fashion brands have made sneakers a core piece of modern wardrobes.
https://yoo.social/read-blog/90366
In addition, sneakers easily fit various styles.
Their popularity is also driven by busy routines.
High-quality sneakers offer long-lasting comfort and support for the feet.
As a result, sneakers have become a must-have item for people of all ages.
Знакомство с новостными источниками имеет большое значение в повседневной жизни.
Оно помогает оставаться информированным и разбираться в текущих процессах.
Оперативная информация позволяют принимать взвешенные решения.
Чтение СМИ способствует повышению осознанности.
https://telegra.ph/Rostov-na-Donu-12-25
Несколько точек зрения помогают видеть картину шире.
В профессиональной сфере СМИ дают возможность следить за тенденциями.
Регулярное изучение материалов формирует информационную грамотность.
В целом, чтение СМИ помогает лучше понимать мир.
Dressing stylishly plays an important role in daily life.
The way a person dresses often creates a positive impression.
Stylish clothing can improve confidence and help people feel more comfortable.
A well-chosen outfit also reflects personality and individual taste.
https://joylife.in/read-blog/397
In professional settings, style may influence how others view a person.
Fashionable clothing does not always mean expensive items, but rather thoughtful choices.
When people dress well, they often feel more confident.
As a result, dressing stylishly helps create a confident look in different situations.
Having a sense of style is essential for self-expression.
A thoughtful appearance helps express personality.
A neat look can boost confidence.
In everyday life, appearance often affects social interactions.
https://telegra.ph/Bottega-Veneta-12-25-14
Carefully selected clothing make communication easier.
It is important to consider personal preferences as well as the context.
Modern styles give people the chance to refresh their image.
Ultimately, dressing stylishly supports a complete personal image.
Thanks for this helpfull post, keep posting
Статья содержит интересные факты, которые помогают глубже понять тему.
Nicely put, With thanks. https://heylink.me/betflik-th
คอนเทนต์นี้ อ่านแล้วเข้าใจง่าย ครับ
ผม ได้อ่านบทความที่เกี่ยวข้องกับ ข้อมูลเพิ่มเติม
ซึ่งอยู่ที่ betflik 24
เผื่อใครสนใจ
มีตัวอย่างประกอบชัดเจน
ขอบคุณที่แชร์ เนื้อหาดีๆ นี้
และหวังว่าจะมีข้อมูลใหม่ๆ มาแบ่งปันอีก
Комплексный bosch diesel service
Турбодизельные двигатели укомплектованы точной электроникой, диагностика которых требует квалификации специалистов.
бош дизель сервис — полный спектр работ по обслуживанию топливной аппаратуры:
• бош сервис ремонт форсунок — ремонт электромагнитных форсунок
• диагностика тнвд — установление дефектов
• бош дизель сервис москва — удобное расположение
• bosch сервис дизель — надежность
Обслуживаем транспорт любых производителей: европейские, корейские, американские.
Преимущества:
– обученный персонал
– качественные комплектующие
– профессиональные стенды
– ответственность за результат
https://dkpodmoskovie.mykrasnogorsk.ru/redirect?url=https://www.adpost4u.com/user/profile/4242082
Всесторонний bosch diesel service
Современные дизельные двигатели оснащены сложными системами, обслуживание которых нуждается в профессионального оборудования.
бош дизель сервис — все виды обслуживания по обслуживанию топливной аппаратуры:
• бош сервис ремонт форсунок — регенерация форсунок Common Rail
• проверка тнвд — выявление неисправностей
• бош дизель сервис москва — доступный адрес
• bosch сервис дизель — гарантия качества
Мы работаем машины различных брендов: французские, японские, отечественные.
Выбирайте нас:
– опытные мастера
– фирменные детали
– новейшая техника
– гарантия
https://onlineschool.ie/index.php/Bosch_Diesel_Service_%D0%BD%D0%B0_%D0%A1%D0%BA%D0%BE%D0%BB%D0%BA%D0%BE%D0%B2%D1%81%D0%BA%D0%BE%D0%BC_%D1%88%D0%BE%D1%81%D1%81%D0%B5
This platform offers a wide range of interesting and practical information.
Visitors are able to access content on many topics.
All materials are thoughtfully arranged and convenient to read.
The site stays current with relevant information.
https://thecropsmith.uk/we-hired-a-new-employee
This makes it a useful destination for everyday use.
When searching for quick answers or in-depth insights, the platform has something to offer.
The information comes in a clear and convenient format.
As a result, this site stands out for a wide audience.
The World State is a gilded cage. The Brave New World PDF shows you the bars. It is a revelation of the limits of a materialist utopia.
Do you want to know what happens on Himmel Street? The answers lie within the pages of this book. Reading The Book Thief PDF is a great way to uncover the fate of its characters. It is a tragedy and a love story wrapped into one unforgettable package.
The World State’s motto is ironic in its application. The Brave New World PDF breaks down the meaning of Identity, Community, Stability. It is a slogan that demands total conformity at the expense of the self. https://bravenewworldpdf.site/ Brave New World Study Questions Pdf
The bond between Hans and his accordion is symbolic of his soul. Read about it in The Book Thief PDF. It shows how art can survive even when the artist is beaten down, a hopeful message for readers everywhere. https://thebookthiefpdf.site/ Percy Jackson And The Lighting Thief Book Pdf
The book concludes that you cannot have civilization without instability. The Brave New World PDF presents this difficult truth. It is a mature, complex novel that respects the intelligence of its reader.
The drug soma is the ultimate escape, but it solves nothing. Read the Brave New World PDF to see how chemical happiness prevents real growth. This digital text is a powerful tool for exploring themes of escapism and the importance of suffering in the human experience. https://bravenewworldpdf.site/ Brave New World Alduous Huxley Pdf
The journey upriver is a metaphor for the journey back to the beginnings of time. Marlow feels as though he is traveling through a prehistoric earth. This sense of timelessness is central to the novel’s atmosphere. If you are looking to study this effect, a Heart of Darkness PDF is a great resource. It allows for quick reference to the specific passages where Conrad describes the overwhelming power of the jungle. The book remains a vital critique of the colonial mindset and a profound exploration of existential dread. https://heartofdarknesspdf.site/ Conrad Heart Of Darkness Pdf
Steinbeck’s classic narrative is often studied in schools for its accessible yet deep critique of social inequality. When Kino finds the great pearl, he envisions a future where his son can read and they can escape poverty. However, the pearl awakens envy in everyone around him, leading to violence and arson. For those preparing for an essay or simply wanting to enjoy a timeless classic, locating a version of the pearl pdf online can provide immediate access to the text. The story is a cautionary tale that questions the true cost of wealth, making it a compelling read for anyone interested in American literature and the human condition. https://thepearlpdf.site/ The Pearl Activities Pdf
Step into the heat of 1940s Algiers. Albert Camus creates a sensory experience where the oppressive sun acts as a catalyst for tragedy. The Stranger is more than just a crime novel; it is a manifesto of existential thought. If you want to read this classic and are searching for a PDF version or an e-book to take with you, you are about to encounter a character who refuses to lie about his feelings. Meursault’s brutal honesty and lack of regret make him one of the most compelling anti-heroes in literature. https://thestrangerpdf.site/ The Stranger Albert Camus In French Pdf
Thanks designed for sharing such a nice opinion, piece of writing is good, thats
why i have read it completely
“Mother died today. Or maybe yesterday; I can’t be sure.” With these opening words, Albert Camus sets the tone for one of the most important novels of the twentieth century. This story of an ordinary man drawn into a senseless murder on an Algerian beach is a staple of modern literature. Whether you are a student searching for The Stranger PDF for a comparative literature class or a casual reader wanting to explore existentialism, this book is essential. The narrative questions whether a man can be judged not for his crime, but for his inability to weep at a funeral.
One of the most intense sequences in literature occurs when Kino and his family must flee their village to escape the dark forces chasing the pearl. The journey through the desert and into the mountains is fraught with danger, culminating in a heartbreaking climax. Accessing the story via a the pearl pdf file allows readers to easily reference these fast-paced chapters. Steinbeck uses the landscape itself as a character, harsh and unforgiving, mirroring the hostility of the townspeople. The final scenes are a testament to the destructive power of greed, leaving the reader with a lingering sense of loss and a lesson that remains relevant today.
บทความนี้ ให้ข้อมูลดี ค่ะ
ดิฉัน เพิ่งเจอข้อมูลเกี่ยวกับ หัวข้อที่คล้ายกัน
ซึ่งอยู่ที่ Trinidad
ลองแวะไปดู
เพราะให้ข้อมูลเชิงลึก
ขอบคุณที่แชร์ เนื้อหาดีๆ นี้
และหวังว่าจะมีข้อมูลใหม่ๆ มาแบ่งปันอีก
Shay’s fight is intense. This book is powerful. The The Last Housewife epub is popular. The plot is gripping. It is a story about freedom. A great book. https://thelasthousewifeepub.site/ Psychological Thriller Books
Ashley Winstead’s This Book Will Bury Me is a storm. It is a book that rains down. The epub version is the umbrella. It covers you in story. The narrative is a deluge. It is a book that will bury you in its weather. If you want a digital book that storms, this is it. Get the epub and get wet.
Shield of Sparrows by Devney Perry is a beautiful story. The shield of sparrows epub is the right way. Digital books are great. Perry’s writing is lovely. The ebook format is easy. If you want a romance, this digital book is it. Add it to your collection.
Un’opera che è un concentrato di poesia pura, dove ogni frase potrebbe essere incorniciata e appesa al muro come promemoria per vivere meglio. Chi cerca il piccolo principe pdf vuole fare sue queste frasi. La storia ci ricorda che l’essenziale è invisibile agli occhi, un invito a chiudere gli occhi fisici per aprire quelli dell’anima e vedere finalmente la realtà per quello che è veramente, al di là delle maschere e delle convenzioni sociali. https://ilpiccoloprincipepdf.site/ Il Piccolo Principe Pdf Free
La delicatezza con cui viene trattato il tema dell’amore, in tutte le sue forme, rende questo libro un manuale di educazione sentimentale senza pari. Chi cerca il piccolo principe pdf trova un maestro d’amore. La storia ci ricorda che addomesticare qualcuno significa creare dei legami che ci rendono unici l’uno per l’altro, trasformando l’indifferenza del mondo in un giardino familiare dove ogni passo ha un suono diverso e ogni ora ha un colore speciale. https://ilpiccoloprincipepdf.site/ Il Piccolo Principe Papa Fracesco Pdf
Tra le pagine di questo libro si nasconde il segreto per restare umani in un mondo che sembra aver dimenticato il valore della gentilezza e dell’ascolto. L’opzione di leggere in digitale, trovando il piccolo principe pdf, permette di portare questo segreto sempre in tasca. La relazione con la rosa ci mostra che l’amore è fatto anche di spine e di incomprensioni, ma che è proprio la cura quotidiana e la pazienza a rendere quel fiore unico al mondo tra migliaia di altri fiori simili.
Se siete alla ricerca di un libro che vi tenga incollati allo schermo del vostro tablet, I giorni dell’eternità è la risposta. L’epilogo della Century Trilogy è denso di avvenimenti cruciali, dalla guerra fredda alla caduta del comunismo. Il formato epub rende giustizia alla mole dell’opera, offrendo un’esperienza di lettura confortevole e personalizzabile. Non c’è modo migliore per apprezzare la maestria di Ken Follett nel tessere trame complesse che coinvolgono personaggi di diverse nazionalità, tutti uniti dal filo invisibile della storia che avanza inesorabile verso il nuovo millennio.
La sfida più grande per Robert Langdon in “L’ultimo segreto”. Un enigma mortale. La versione pdf è ideale per chi viaggia. La storia è un mix di azione e cultura. Scopri la verità e lasciati conquistare.
I destini di americani, russi, tedeschi e inglesi si incrociano ancora una volta in I giorni dell’eternità, il romanzo che chiude la Century Trilogy. Ken Follett ci porta dentro la storia con una forza narrativa unica. Scaricare l’epub significa assicurarsi un posto in prima fila per assistere agli eventi che hanno cambiato il mondo. La lettura digitale esalta la scorrevolezza del testo, permettendovi di divorare le pagine una dopo l’altra. Preparatevi a un finale emozionante che ripaga di tutte le attese, in un formato pratico e moderno.
The mystery of the Lee family is waiting to be solved. Find the Everything I Never Told You PDF and uncover the truth. It is a book that will surprise you. It is a story that is deeper than it seems. It is a modern classic. https://everythinginevertoldyoupdf.site/ Everything I Never Told You Pdf With Page Numbers
Join the millions who have been moved by this story. Find the Everything I Never Told You PDF and start reading today. It is a book that connects us all. It is a story of the secrets we keep and the love that saves us. It is everything. https://everythinginevertoldyoupdf.site/ Everything I Never Told You Pdf Español
There is a rhythm to Maas’s writing that is hypnotic. once you start reading, it is hard to stop. A Queen of Shadows pdf facilitates this binge-reading behavior. The sentences flow, the action propels you forward, and the characters keep you engaged. It is a perfect storm of storytelling elements. Whether you are a long-time fan or a newcomer, this book delivers on every level. It is the gold standard for YA fantasy. https://queenofshadowspdf.site/ Queen Of Shadows Sarah J Maas Pdf Free Download
Heya i’m for the first time here. I came across this board and I find It really
useful & it helped me out a lot. I hope to give something back and help
others like you helped me.
We notice health more than we think, even when we don’t name it.
With so much information, the meaning often gets diluted.
Bodies speak in personal signals, but advice is often broad and generic.
When we dismiss it, we weaken our connection to ourselves.
What supports one person can drain another.
And step by step, it rebuilds trust between mind and body.
Over time, health stops feeling like an outside target and becomes part of identity.
And with time, that quiet becomes resilience.
When slowing down feels like the missing step forward.
To notice what your body has been trying to communicate.
And letting balance appear naturally, in its own time.
And with each realization, we move closer to genuine balance.
Awareness and physiology meet right where personal experience begins.
You may be asking how all of this ties into super kamagra interactions.
The novel is a great conversation starter. Everyone has an opinion on Darcy. To join the debate, you need to know the facts. A digital version gives you the evidence. If you are looking for a Pride and Prejudice PDF, you are preparing for a discussion. Our website supports the discourse around the book. Be ready to defend your favorite character.
Two families, one house, a million memories. Jenny Han builds a monument to shared history. If you are looking for “The Summer I Turned Pretty PDF,” you are looking for a saga. The story is about the intertwining lives of the Conklins and Fishers. It is a rich tapestry of relationships. It is a complex and rewarding read. https://thesummeriturnedprettypdf.site/ The Summer I Turned Pretty Trilogy Epub
Family traditions can be a comfort or a cage. Jenny Han explores this duality. If you are searching for “The Summer I Turned Pretty PDF,” you will find a story about legacy. The mothers want the children to be close, but the children are growing up. The story is about breaking free from expectations. It is a thoughtful and interesting read. https://thesummeriturnedprettypdf.site/ The Summer I Turned Pretty Third Book Pdf
The relationship between Belly and her mother is just as important as the romance. Jenny Han gives equal weight to family dynamics. If you are looking for the PDF, you will find a balanced story. “The Summer I Turned Pretty” is about the difficulty of growing up and pulling away from your parents. It is also about the enduring bond of family. It is a touching and well-rounded novel. https://thesummeriturnedprettypdf.site/ The Summer I Turner Pretty Pdf
Why do we hold onto summer so tightly? Perhaps because it is fleeting, just like youth. Jenny Han explores this theme beautifully. If you are searching for “The Summer I Turned Pretty PDF,” you are in for a treat. The story of the Fisher boys and the Conklin women is intertwined with secrets and love. It offers a nostalgic look at the traditions that bind us. Whether you are Team Conrad or Team Jeremiah, the journey is worth every page. It is a modern classic.
A beach house, two brothers, and one girl. It is a recipe for drama. Jenny Han cooks up a storm in this novel. The PDF version allows you to read the story anywhere. The Summer I Turned Pretty is about the realization that you can’t control who you fall for. Belly’s journey is one of self-discovery and heartache. The writing is lush and atmospheric. It is a book that will stay with you.
Edna’s husband, Léonce, treats her like a possession, looking at her as one looks at a valuable piece of personal property. This dynamic sets the stage for her rebellion. To analyze the gender politics of the novel, access the awakening pdf. It provides a stark look at the legal and social status of women in the 19th century. The text is a historical document as much as a work of fiction. A digital copy allows you to annotate the most infuriating and inspiring moments of the story. https://theawakeningpdf.store/ The Awakening Worksheet Pdf
Orwell wrote this book during World War II, yet it speaks to every generation. Its insights into human nature are timeless. Whether it is the greed of the pigs or the loyalty of the horses, we see ourselves in these characters. Finding an Animal Farm PDF is the first step to joining the global conversation about this book. It is a shared cultural touchstone that helps us understand the world. https://animalfarmpdf.store/ Animal Farm Lit Chart Pdf
Few endings in literature are as debated and analyzed as the conclusion of Kate Chopin’s only novel. To form your own opinion on whether Edna’s final act is a triumph or a tragedy, you need to read the full text. Many literary enthusiasts look for the awakening pdf to access the unbridled version of the story. The narrative flow, from the languid days at Grand Isle to the frantic emotions in New Orleans, is best experienced without interruption. A portable document format allows you to keep this profound story with you, ready to read whenever inspiration strikes. https://theawakeningpdf.store/ The Awakening Multiple Choice Test Pdf
Mark Twain’s masterpiece is a joy to read. The Adventures of Tom Sawyer is filled with memorable characters and exciting plot twists. We provide a digital version of the text that is compatible with all e-readers. If you are looking for a convenient way to read this classic, look no further. A Tom Sawyer PDF ensures that you have instant access to the story, complete with all the humor and heart that Twain is known for. https://tomsawyerpdf.store/ Tom Sawyer Download Epub
The eventual return of the farm’s name to “Manor Farm” signifies the full circle of the narrative. Nothing has changed for the better; in fact, things may be worse. This cyclical view of history is pessimistic but thought-provoking. Readers often seek the Animal Farm PDF to analyze this ending. It suggests that without structural change, revolutions merely swap one set of masters for another. https://animalfarmpdf.store/ Chapter Nine Animal Farm Pdf
If you are tired of formulaic bestsellers, try a classic that breaks all the rules. The Awakening is unpredictable and challenging. Search for the awakening pdf to shake up your reading list. The digital text is a gateway to a different kind of storytelling.
Enter a world of superstition, youthful romance, and buried gold. The Adventures of Tom Sawyer is a thrilling ride from start to finish. Our platform provides the full text in a convenient digital format. If you are tired of squinting at small print in old paperbacks, our optimized digital version will be a relief. Get your Tom Sawyer PDF today and enjoy the flexibility of adjusting the text size and background to suit your reading preferences.
“She was becoming herself and daily casting aside that fictitious self which we assume like a garment with which to appear before the world.” This is the essence of the book. To find your own true self, read the awakening pdf. It is a guide to stripping away the inessential. The digital text is a mirror for the soul.
The story involves a race against time. The Soulmonger is devouring souls, and resurrection is impossible. This urgency defines the campaign. The Tomb of Annihilation PDF outlines the progression of the curse. DMs use the digital timeline to track the decay of important NPCs. It keeps the pressure high. The PDF also details the villainous factions, like the Red Wizards, who are also racing to the tomb. Managing these competing interests is easier with a digital reference that explains their motivations and current locations in the jungle.
The “Holy Weapon” spell is a Paladin and Cleric favorite introduced here. Xanathar’s Guide to Everything adds significant damage buffs for divine casters. Players looking for a PDF of the spell damage scaling should read our divine striker guide. We calculate the output of a Paladin with this spell active. Smite with the fury of the gods using the powerful new evocations in this tome. https://xanatharsguidetoeverythingpdf.ru/ 5E D&D Xanathar’s Guide To Everything Pdf
Thresh and his mercy toward Katniss show that honor still exists even in the arena. These small moments of humanity define the moral core of the story. It is a complex narrative that refuses to see people as purely good or evil. To appreciate the character nuances, reading the novel is essential. Whether you choose a paperback or a The Hunger Games pdf, the important thing is to witness the choices these characters make under extreme pressure. https://thehungergamespdf.ru/ The Hunger Games 1 Pdf Free Download
For those who love a good grovel, Dante’s realization of his feelings provides a satisfying arc. He has to work to win Vivian back after pushing her away. This redemption is crucial. A King of Wrath PDF allows you to witness his humility. It balances out his arrogance from the beginning of the book. https://kingofwrathpdf.ru/ King Of Wrath Read Online Free Pdf
From cover to cover, Xanathar’s Guide to Everything provides the crunch players crave. It balances flavor with hard mechanics perfectly. If you are searching for a PDF review that rates every single subclass, our mega-guide is ready. We rank the options from S-tier to D-tier to help you choose. Make the most of your character creation process with our critical analysis of this D&D masterpiece.
The dialogue often has double meanings, layering the text with subtext. Dante says one thing but means another; Vivian decodes him. This interplay is brilliant. A King of Wrath PDF read allows you to catch these subtleties. It makes the re-read value very high. You see the signs of their falling in love long before they admit it.
Он/она не стремится принимать сторону и предоставляет читателям возможность самостоятельно сделать выводы.
Я хотел бы выразить свою благодарность автору этой статьи за исчерпывающую информацию, которую он предоставил. Я нашел ответы на многие свои вопросы и получил новые знания. Это действительно ценный ресурс!
Whats up this is somewhat of off topic but I was wanting to
know if blogs use WYSIWYG editors or if you have
to manually code with HTML. I’m starting a blog soon but have no coding
knowledge so I wanted to get guidance from someone with experience.
Any help would be greatly appreciated!
Dressing stylish projects a strong first impression.
Your attire speaks volumes before you actually speak a word.
It boosts your personal self-esteem and mood noticeably.
A put-together appearance conveys professionalism in the workplace.
https://z2.sochidaily.ru/f2WgVK2/
Fashionable choices allow you to showcase your unique identity.
Others often judge well-dressed people as more successful and reliable.
Therefore, putting effort in your style is an investment in your personal brand.
Looking well creates a strong first impression.
A outfit communicates loudly before a person even say a word.
This boosts your personal confidence and mindset significantly.
Your put-together look signals competence in the workplace.
https://list.chenews.ru/0dQzGY8EL/
Fashionable choices allow you to showcase your unique identity.
People often judge stylish people as more capable and reliable.
Therefore, putting effort in your wardrobe is an valuable step in yourself.
Стильный вид формирует сильное впечатление о вас.
Ваш образ работает на восприятие вас окружающими сразу.
Хорошее самочувствие в подобранном луке повышает личную уверенность.
Он демонстрирует ваш уровень ответственности и внимание к мелочам.
https://b3.hypebeasts.ru/redirect.php?id=BKSAhDJR3cYY
Через гардероб вы имеете шанс проявить свою индивидуальность и стиль.
Люди часто оценивают стильных людей как более успешных.
Поэтому, вложения в свой образ — это вклад в ваше успешное будущее.
Premium watches continue to hold strong appeal despite the rise of modern gadgets.
They are often seen as a symbol of status and refined taste.
Skilled engineering plays a major role in their lasting value.
Many luxury watches are produced using carefully selected materials.
https://truckymods.io/user/452428
They also represent a rich heritage passed down through generations.
For collectors, these watches can serve as both wearable tools and collectible pieces.
Elegant styling allows them to stay relevant across changing fashion trends.
In the end, luxury watches continue to interest buyers around the world.
Looking well creates a positive first impression.
Your outfit communicates loudly before you even speak a word.
This boosts your personal self-esteem and mood significantly.
Your put-together appearance signals professionalism in the workplace.
https://links.mvmedia.ru/UVPVx5/
Fashionable clothing allow you to express your unique personality.
Others often judge stylish people as more successful and reliable.
Therefore, investing in your style is an investment in your personal brand.
เนื้อหานี้ น่าสนใจดี ครับ
ดิฉัน ไปเจอรายละเอียดของ หัวข้อที่คล้ายกัน
สามารถอ่านได้ที่ luck168
น่าจะถูกใจใครหลายคน
เพราะอธิบายไว้ละเอียด
ขอบคุณที่แชร์ บทความคุณภาพ นี้
และหวังว่าจะมีข้อมูลใหม่ๆ มาแบ่งปันอีก
Мне понравилось объективное представление разных точек зрения на проблему.
Hello there! I just would like to give you a huge thumbs up for your excellent info you’ve got here on this post. I’ll be returning to your web site for more soon.
ข้อมูลชุดนี้ อ่านแล้วได้ความรู้เพิ่ม ค่ะ
ดิฉัน ได้อ่านบทความที่เกี่ยวข้องกับ ข้อมูลเพิ่มเติม
สามารถอ่านได้ที่
เว็บสล็อต
เผื่อใครสนใจ
เพราะให้ข้อมูลเชิงลึก
ขอบคุณที่แชร์ ข้อมูลที่มีประโยชน์ นี้
จะรอติดตามเนื้อหาใหม่ๆ ต่อไป
Это помогает читателям получить полное представление о спорной проблеме.
Автор статьи предоставляет факты и аргументы, не влияя на читателя своими собственными предпочтениями или предвзятостью.
Автор старается оставаться объективным, чтобы читатели могли сформировать свое собственное мнение на основе предоставленной информации.
Looking stylish projects a strong first impression.
Your outfit speaks loudly before you even speak a single word.
This boosts your personal self-esteem and mindset noticeably.
Your put-together appearance signals professionalism in the workplace.
https://urls.mvmedia.ru/ra6Fijs16eO3/
Stylish clothing let you to express your individual personality.
People often judge stylish people as more capable and reliable.
Therefore, putting effort in your style is an investment in yourself.
Looking well projects a positive first impression.
Your attire communicates volumes before you actually speak a word.
It boosts your own confidence and mood noticeably.
Your polished look signals competence in the office.
https://b3.hypebeasts.ru/oTdiV2/
Fashionable clothing allow you to express your unique identity.
People often perceive stylish people as more capable and reliable.
Ultimately, putting effort in your wardrobe is an valuable step in your personal brand.
Dressing stylish projects a positive first impression.
A attire communicates loudly before a person even say a single word.
This enhances your personal confidence and mood noticeably.
Your put-together appearance conveys professionalism in the workplace.
https://r5.balmain1.ru/VPRqLFuUpW/
Stylish clothing allow you to showcase your unique personality.
People often perceive stylish people as more successful and reliable.
Ultimately, investing in your style is an valuable step in your personal brand.
Dressing stylish creates a positive first impression.
A attire communicates loudly before you even say a single word.
It enhances your personal self-esteem and mindset noticeably.
A put-together appearance conveys competence in the workplace.
https://a2.gucci1.ru/vKqwmdRSjB/
Stylish clothing allow you to showcase your individual personality.
Others often perceive well-dressed people as more successful and reliable.
Ultimately, putting effort in your wardrobe is an valuable step in yourself.
Along with everything which appears to be developing throughout this particular area, your perspectives happen to be relatively refreshing. Nonetheless, I am sorry, but I can not give credence to your entire idea, all be it stimulating none the less. It would seem to me that your comments are not entirely justified and in reality you are generally your self not really completely convinced of the argument. In any case I did appreciate examining it.
Оперативный выкуп авто является всё очень востребованной опцией.
Это дает шанс продавцу быстро обрести наличные за транспорт.
Автовладельцев привлекает отсутствие времени на долгие переговоры с клиентами.
Компании осматривают авто на выезде и называют реальную цену.
Подобный подход избавляет от сложностей с оформлением и обещает надежность операции.
https://blog.lasuper.ru/srochnyy-vykup-avto-v-kaliningrade-ot-kompanii-kenigauto39/
Я чувствую, что эта статья является настоящим источником вдохновения. Она предлагает новые идеи и вызывает желание узнать больше. Большое спасибо автору за его творческий и информативный подход!
Автор старается сохранить нейтральность, предоставляя обстоятельную основу для дальнейшего рассмотрения темы.
The website contains a great deal of valuable content.
You can access detailed guides on various subjects.
All information is organized in a user-friendly format.
It’s a perfect destination for those looking insights.
https://www.gladaankan.com
You said it nicely.. https://pad.stuve.uni-ulm.de/s/i0yrtcnX8d
Опрятный вид создает сильное впечатление о человеке.
Он влияет на восприятие вас окружающими мгновенно.
Уверенность в своем образе повышает вашу уверенность.
Он демонстрирует высокий стандарт ответственности и внимание к деталям.
https://n4.vladtoday.ru/kZ6qT4tND9HN/
Через одежду вы имеете шанс выразить свою личность и стиль.
Люди часто воспринимают стильных индивидов как более успешных.
Поэтому, инвестиции в свой образ — это вклад в свое успешное будущее.
บทความนี้ ให้ข้อมูลดี ค่ะ
ดิฉัน ไปเจอรายละเอียดของ เรื่องที่เกี่ยวข้อง
ที่คุณสามารถดูได้ที่ Ina
สำหรับใครกำลังหาเนื้อหาแบบนี้
เพราะให้ข้อมูลเชิงลึก
ขอบคุณที่แชร์ เนื้อหาดีๆ
นี้
จะรอติดตามเนื้อหาใหม่ๆ ต่อไป
You have made some decent points there. I looked on the net for additional information about the issue and found most individuals will go along with your views on this site.
gnc weight loss products
References:
https://notes.bmcs.one/s/jh8FKcNa6
Apologies for the off-topic reply, but this point is still worth making. Health keeps influencing daily experience even when it goes unnamed, and it affects how we feel, function, and handle stress. The difficult part is that guidance is now coming from every direction, but constant input often makes it harder to see what matters. That usually happens when nuance gets stripped out, and what should stay personal starts sounding standard. That is where advice and real life begin to separate, because biology does not follow one universal pattern. This is often where the body starts communicating more clearly, through poor recovery, irritability, or scattered attention. That is why awareness often comes before improvement, paying attention to repeated signals, so that progress feels realistic rather than forced. This is where a real health conversation becomes valuable, because it keeps the focus on understanding instead of oversimplifying. So if you want a more grounded way to think about health, the most direct way to continue is with iMedix medical research.
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make your point. You clearly know what youre talking about, why waste your intelligence on just posting videos to your weblog when you could be giving us something informative to read?
คอนเทนต์นี้ มีประโยชน์มาก ครับ
ดิฉัน เพิ่งเจอข้อมูลเกี่ยวกับ เนื้อหาในแนวเดียวกัน
สามารถอ่านได้ที่ สล็อตแตกง่าย
เผื่อใครสนใจ
มีตัวอย่างประกอบชัดเจน
ขอบคุณที่แชร์ บทความคุณภาพ นี้
และอยากเห็นบทความดีๆ
แบบนี้อีก
Сваи выполняют важнейшую функцию в строительстве прочного основания.
Они позволяют правильно распределить нагрузку от постройки на почву.
Использование свай крайне актуально на слабых участках с большим уровнем влаги.
Данный тип опор гарантирует стабильность конструкции при подвижках земли.
https://www.chordie.com/forum/profile.php?id=2479009
Свайное решение способно переносить серьёзные воздействия в том числе в сложных регионах.
Помимо этого, подобный фундамент требует меньше объём земляных мероприятий.
Таким образом, грамотный выбор конструкций обеспечивает долговечность всего объекта.
Reputation management is the strategic practice of influencing public perception of a company or individual.
It involves actively monitoring what is being discussed about you on the internet.
The goal is to promote favorable content and address any damaging feedback or criticism.
This often includes responding to customer reviews on various platforms.
https://forums.hostsearch.com/member.php?287577-repuhouse
A vital part is managing search engine results for associated search terms.
Effective ORM helps build credibility and protect a strong digital image.
Ultimately, it is an essential practice for any contemporary business or public figure.
References:
The point casino
References:
http://en.bixink.com/28/?bmode=view&idx=3805231
casino victoria
References:
https://dg-kfz-gutachten.de/daniel_gecic_begutachtung_motorschaeden
casino gran madrid
References:
https://doc.adminforge.de/s/PslCDZ4LxH
Dressing well creates a positive first impression.
A outfit communicates loudly before a person even say a single word.
This enhances your own confidence and mood noticeably.
A polished appearance signals professionalism in the workplace.
https://blog.superpodium.com/gedonizm-v-iskusstve-estetika-udovolstviya-6799619/
Fashionable choices let you to showcase your unique identity.
Others often perceive well-dressed individuals as more capable and reliable.
Therefore, investing in your style is an investment in your personal brand.
ข้อมูลชุดนี้ อ่านแล้วได้ความรู้เพิ่ม ค่ะ
ดิฉัน เพิ่งเจอข้อมูลเกี่ยวกับ ข้อมูลเพิ่มเติม
ซึ่งอยู่ที่ Mohamed
น่าจะถูกใจใครหลายคน
มีตัวอย่างประกอบชัดเจน
ขอบคุณที่แชร์ คอนเทนต์ดีๆ นี้
จะรอติดตามเนื้อหาใหม่ๆ ต่อไป
Читателям предоставляется возможность обдумать и обсудить представленные факты и аргументы.
Автор статьи предоставляет различные точки зрения и экспертные мнения, не принимая сторону.
Читателям предоставляется возможность ознакомиться с различными аспектами темы и сделать собственные выводы.
hi!,I really like your writing so much! proportion we be in contact more approximately your post on AOL? I need a specialist on this area to resolve my problem. Maybe that’s you! Taking a look forward to look you.
Я бы хотел отметить качество исследования, проведенного автором этой статьи. Он представил обширный объем информации, подкрепленный надежными источниками. Очевидно, что автор проявил большую ответственность в подготовке этой работы.
I have read so many articles or reviews regarding the blogger lovers however this paragraph is truly a nice paragraph, keep it up.
удаленная работа без опыта Особенно привлекательна удаленная работа без опыта, открывающая двери для студентов, мам в декрете и даже подростков, позволяя им приобрести ценные навыки и заработать, не отрываясь от повседневных дел.
With havin so much content and articles do you ever run into any problems of plagorism or copyright violation?
My blog has a lot of exclusive content I’ve either authored myself or outsourced but it seems a lot of it is popping
it up all over the internet without my permission. Do
you know any solutions to help reduce content from being
stolen? I’d truly appreciate it.
certainly like your website but you need to take a look at the spelling on several of your posts. Many of them are rife with spelling problems and I to find it very troublesome to inform the reality nevertheless I will surely come back again.
Dressing stylish creates a positive first impression.
A outfit communicates loudly before a person actually speak a single word.
This boosts your own self-esteem and mindset noticeably.
A polished appearance signals competence in the office.
https://photo-art.fashionsecret.ru/roskoshnye-puteshestviya-kak-organizovat-idealnyy-otdykh-7742238/
Stylish clothing allow you to express your individual identity.
Others often perceive well-dressed individuals as more successful and reliable.
Therefore, putting effort in your wardrobe is an valuable step in yourself.
โพสต์นี้ มีประโยชน์มาก ครับ
ผม เพิ่งเจอข้อมูลเกี่ยวกับ เรื่องที่เกี่ยวข้อง
ซึ่งอยู่ที่ เว็บสล็อต betfliknew
น่าจะถูกใจใครหลายคน
เพราะอธิบายไว้ละเอียด
ขอบคุณที่แชร์ คอนเทนต์ดีๆ นี้
และอยากเห็นบทความดีๆ แบบนี้อีก
Hey there this is kind of of off topic but I was wanting to know if blogs use WYSIWYG editors or if you have to manually code with HTML. I’m starting a blog soon but have no coding skills so I wanted to get advice from someone with experience. Any help would be enormously appreciated!
Очень понятная и информативная статья! Автор сумел объяснить сложные понятия простым и доступным языком, что помогло мне лучше усвоить материал. Огромное спасибо за такое ясное изложение! Это сообщение отправлено с сайта https://ru.gototop.ee/
Важно отметить, что автор статьи предоставляет информацию с разных сторон и не принимает определенной позиции.
&&*LowPrice&HighQuality-Guestpost【dr50+real-traffic】Telegram @buycasinolink
Статья содержит актуальную информацию по данной теме.
Heya i am for the first time here. I came across this board and I to find It truly helpful & it helped me out much. I hope to provide one thing back and help others like you helped me.
Online gaming platforms are immensely widespread due to their unmatched convenience.
Players can enjoy their preferred games anytime and from anywhere with an online connection.
The thrill of playing for actual cash introduces an additional layer of adrenaline.
A vast array of options caters to all taste and budget.
Bonuses and loyalty programs provide added incentives to retain players coming back.
Modern platforms ensure safe transactions and fair gameplay.
https://www.hrdp-idrm.in/
This piece of writing will assist the internet visitors for setting up
new website or even a blog from start to end.
Inspiring story there. What happened after? Take care!
I got this web site from my pal who shared with me about this site
and at the moment this time I am visiting this website and
reading very informative posts at this place.
When someone writes an article he/she maintains the thought of a user in his/her mind that how a user can understand it.
So that’s why this piece of writing is perfect.
Thanks!
Продуманный внешний вид играет важную роль в формировании образа.
Она помогает выразить характер и почувствовать уверенность.
Аккуратный стиль влияет на то, как человека оценивают другие люди.
В повседневной жизни одежда может создавать ощущение собранности.
https://read.e-copies.ru/innovatsionnye-materialy-v-dizayne-ferragamo-put-k-ustoychivosti-6883565/
Стильный образ облегчает социальные контакты.
При этом важно учитывать собственный вкус и обстановку.
Стиль дают возможность находить новые решения.
Таким образом, умение стильно одеваться влияет на общее восприятие личности.
Я хотел бы выразить свою восторженность этой статьей! Она не только информативна, но и вдохновляет меня на дальнейшее изучение темы. Автор сумел передать свою страсть и знания, что делает эту статью поистине уникальной.
Entscheiden Sie sich für einen geschätzten und von über 6.900 Menschen in ganz Europa genutzten Service um in wenigen Tagen zum Führerschein zu kommen, Fahrprüfungen, Fahrverbote, Führerscheinentzug können Sie mit uns ganz einfach vermeiden.
Deutschen Führerschein kaufen
1. Führerschein ohne Prüfung kaufen:
Mit unserem Service können Sie ganz einfach einen Führerschein ohne Prüfung erwerben. Wir helfen Ihnen, Fahrverbote, Führerscheinentzüge oder -sperren sowie die Auflagen der MPU zu vermeiden. Sie können bei uns einen deutschen Führerschein, einen Führerschein aus anderen EU-Ländern und mehr erwerben. Schildern Sie uns Ihr Anliegen – wir bieten Ihnen eine Vielzahl von Optionen.
Führerscheine aus über 30 Ländern kaufen
We offer a completely legal driver’s license for anyone looking to obtain a driver’s license quickly and easily without the need to meet all the requirements.
Our service is unlike any other, we do not aim to produce or register your driving license ourselves, we simply make the process of obtaining your driving license easy and also eliminate the need for you to fulfill all the requirements that are normally needed.
Buy driving license online
Kaufen Sie ganz einfach einen deutschen, polnischen, rumänischen, österreichischen oder tschechischen Führerschein – ganz ohne MPU oder Prüfung.
Erhalten Sie Ihren Führerschein in nur wenigen Tagen. Wir bieten alle Führerscheinklassen an und helfen jedem in Deutschland, seinen Führerschein ohne großen Aufwand zurückzubekommen.
Testen Sie unsere Dienste noch heute und werden Sie einer unserer zufriedenen Kunden, deren Führerscheinprobleme innerhalb weniger Tage gelöst wurden.
Besuchen Sie unsere Website
common steroid names
References:
https://guerrero-slaughter-4.blogbright.net/hormone-de-croissance-musculation-meilleur-prix
injectable amino acids bodybuilding
References:
https://sysurl.online/olenbertram156
I appreciate, cause I found exactly what I was looking for. You’ve ended my four day long hunt! God Bless you man. Have a nice day. Bye
It’s difficult to find knowledgeable people about this topic, but you seem like you know what
you’re talking about! Thanks
Hello, I want to subscribe for this web site to take latest updates, thus where can i do it please help out.
Стильная одежда играет важную роль в создании первого впечатления.
Она помогает подчеркнуть индивидуальность и выглядеть гармонично.
Современный стиль создаёт впечатление окружающих.
В повседневной жизни одежда может помогать собранности.
https://www.registrofiatbarchetta.com/viewtopic.php?f=17&t=238519&p=1854001
Продуманный гардероб облегчает деловое общение.
При выборе одежды важно учитывать личные предпочтения и контекст.
Современные тенденции дают возможность находить новые решения.
Таким образом, умение стильно одеваться делает образ завершённым.
deca steroid pills
References:
https://www.giveawayoftheday.com/forums/profile/1623465
Сейчас кроссовки обрели огромную известность повсеместно.
Такую обувь носят представители разных поколений и профессий.
Ключевая причина столь всеобщей любви — комфорт и универсальность.
оригинальные кроссовки Мизуно
Известные бренды регулярно выпускают свежие линейки, подогревая ажиотаж.
Сникерсы надёжно закрепились в уличную моду и стиль жизни.
С каждым годом их популярность лишь возрастает.
Умение стильно одеваться имеет большое значение в самовыражении.
Она помогает подчеркнуть индивидуальность и ощущать внутренний комфорт.
Аккуратный внешний вид влияет на восприятие окружающих.
В повседневной жизни одежда может придавать уверенность.
http://forum.fiilis.org/viewtopic.php?t=383
Продуманный гардероб облегчает деловое общение.
При выборе одежды важно учитывать индивидуальные особенности и контекст.
Мода дают возможность экспериментировать.
В итоге, умение стильно одеваться помогает чувствовать себя увереннее.
best muscle gainer pill
References:
https://chessdatabase.science/wiki/Where_To_Buy_Testosterone_Online_Clinics_Cheapest_Legal
what happens if you take steroids
References:
https://wolfe-forrest-2.mdwrite.net/7-best-sites-to-buy-testosterone-online-in-2026-1774974838
I was able to find good advice from your articles.
Подлинная дикая красная икорка известна глубоким вкусовым букетом.
Паюсная камчатского происхождения продукция представляет собой настоящим деликатесом.
Эти типа икорного сырья вылавливаются в экологически чистых угодьях Камчатки.
икра лососевая купить
В силу холодным климатическим факторам продукция вызревает особенно питательной.
Качественная камчатская продукция не имеет химии и искусственных красителей.
Выбирая такую продукцию, вы получаете безупречное совершенство вкуса.
เนื้อหานี้ มีประโยชน์มาก ครับ
ดิฉัน ไปอ่านเพิ่มเติมเกี่ยวกับ หัวข้อที่คล้ายกัน
ดูต่อได้ที่ สล็อตออนไลน์
น่าจะถูกใจใครหลายคน
มีการยกตัวอย่างที่เข้าใจง่าย
ขอบคุณที่แชร์ บทความคุณภาพ นี้
จะรอติดตามเนื้อหาใหม่ๆ ต่อไป
Умение стильно одеваться является значимым фактором в создании первого впечатления.
Она помогает передать личный стиль и выглядеть гармонично.
Грамотно подобранный образ формирует мнение окружающих.
В повседневной жизни одежда может помогать собранности.
http://www.lada-xray.net/showthread.php?p=109956#post109956
Хорошо подобранная одежда облегчает социальные контакты.
При выборе одежды важно учитывать личные предпочтения и контекст.
Современные тенденции дают возможность обновлять образ.
В целом, умение стильно одеваться положительно влияет на самоощущение.
บทความนี้ อ่านแล้วได้ความรู้เพิ่ม ครับ
ดิฉัน ไปเจอรายละเอียดของ
ข้อมูลเพิ่มเติม
ดูต่อได้ที่ 12play
น่าจะถูกใจใครหลายคน
เพราะอธิบายไว้ละเอียด
ขอบคุณที่แชร์ เนื้อหาดีๆ นี้
และหวังว่าจะได้เห็นโพสต์แนวนี้อีก
Автор представляет сложные темы в понятной и доступной форме.
Надеюсь, вам понравятся эти комментарии!
I really enjoy reading through on this site, it contains fantastic blog posts.
Автор статьи представляет различные точки зрения и факты, не выражая собственных суждений.
Статья представляет анализ разных точек зрения на проблему, что помогает читателю получить полное представление о ней.
References:
https://graph.org/Casino-Games-You-Need-to-Play-04-20 rocket desktop version
В наше время кроссовки завоевали огромную популярность повсеместно.
Такую обувь носят представители всевозможных поколений и профессий.
Основная причина столь всеобщей любви — комфорт и практичность.
https://www.tumblr.com/sneakerizer/812759018572578816/loewe-%D0%BA%D0%BE%D0%B3%D0%B4%D0%B0-%D0%BA%D0%BE%D0%B6%D0%B0-%D0%B3%D0%BE%D0%B2%D0%BE%D1%80%D0%B8%D1%82-%D0%BD%D0%B0-%D1%8F%D0%B7%D1%8B%D0%BA%D0%B5-%D1%81%D1%8E%D1%80%D1%80%D0%B5%D0%B0%D0%BB%D0%B8%D0%B7%D0%BC%D0%B0
Известные марки постоянно представляют новые коллекции, подогревая интерес.
Сникерсы прочно закрепились в уличную культуру и повседневность.
С каждым сезоном их популярность только увеличивается.
Статья предлагает объективный обзор исследований, проведенных в данной области. Необходимая информация представлена четко и доступно, что позволяет читателю оценить все аспекты рассматриваемой проблемы.
Trải nghiệm thương hiệu xổ số độc quyền đến từ 888slot. khi truy cập sảnh lô đề. Bên cạnh xổ số kiến thiết, người chơi còn có cơ hội thử sức với các sản phẩm mới lạ như: Xổ số siêu tốc, xổ số VIP, Mega 6/45 và xổ số Thái Lan. Tỷ lệ ăn thưởng gấp 99.6 lần tiền cược ban đầu. TONY04-17
Мне понравилось разнообразие и глубина исследований, представленных в статье.
Hey I know this is off topic but I was wondering if you knew of any widgets I could add to my blog that automatically tweet my newest twitter updates. I’ve been looking for a plug-in like this for quite some time and was hoping maybe you would have some experience with something like this. Please let me know if you run into anything. I truly enjoy reading your blog and I look forward to your new updates.
Appreciate it! Plenty of forum posts.
https://bkkcasino.fotosdefrases.com/sl-xt-thdlxng-len-sl-xtweb-trng-thdlxng-len-kb-web-trng
Ordering drugs online is very convenient.
One can order 24/7 without leaving home.
Online pharmacies allow you to easily check prices and spot the lowest deal.
kamagra oral jelly sildenafil
Your order is shipped straight to your address, cutting time and hassle.
Also, there is no need to wait in annoying lines at a local pharmacy.
For those with chronic conditions, automatic reorders make treatment hassle‑free.
Overall, digital shopping for meds preserves your hours and peace of mind.
Seriously plenty of good tips! https://app.readthedocs.org/profiles/barberflute22/
References:
Online casino test
References:
https://casino1-casino.online-spielhallen.de/
References:
Paradice casino
References:
https://red-stag-casino.online-spielhallen.de/
Часы AP Royal Oak славятся своим революционным внешним видом.
Их восьмигранный ободок с открытыми винтами стал подлинной легендой в часовом мире.
Модель была выпущена в далёком 1972-м как первые в мире роскошные часы для спорта из стали.
Подобная дерзкая идея тогда произвела настоящий фурор в часовой индустрии.
заказать Audemars Piguet Royal Oak
Помимо дизайна, модель ценятся за высочайшее исполнение отделки и механизма.
Общеизвестно, что любой образец собирается собственноручно квалифицированными часовщиками.
Сегодня Royal Oak являются эталоном положения и тонкого вкуса.
Именно так они востребованы как среди знатоков, так и у поклонников роскоши.
References:
Choctaw casino durant
References:
https://graph.org/Casino-In-Hobart-Australia-Map-04-27
Buying medications online is incredibly convenient.
One can order 24/7 with no leaving home.
Online pharmacies allow you to quickly check costs and find the lowest deal.
nizagara for erectile dysfunction
Your order is delivered straight to your doorstep, saving time and hassle.
Plus, there is no requirement to stand in annoying lines at a brick-and-mortar store.
For chronic illnesses, automatic reorders ensure therapy hassle‑free.
Overall, digital shopping for meds saves your hours and energy.
Fantastic stuff. Many thanks. https://storage.googleapis.com/member-betflix22/%E0%B8%97%E0%B8%B2%E0%B8%87%E0%B9%80%E0%B8%82%E0%B9%89%E0%B8%B2-betflix/index.html
Hola! I’ve been following your web site for a
long time now and finally got the bravery to go ahead and give you a shout out from
Porter Texas! Just wanted to mention keep up the fantastic job!
Ответственная игра в i-gaming подразумевает управление над временем и деньгами.
Это политика помогает пользователю оставаться в пределах личного лимита.
Основные принципы включают ограничение сумм, паузы в сессии и анализ поведения.
Инструменты добросовестной активности дают установить лимиты на депозиты и потери.
Данный подход защищает от аддикции и необдуманных рисков.
Игроку необходимо воспринимать к игре как к развлечению, а не источнику дохода.
В итоге, ответственная игра делает онлайн-гемблинг в контролируемое развлечение.
vovan casino промокод
With thanks. I appreciate it. https://github.com/sushijala168888-coder
Часы AP 15407ST является выдающимся образцом в часовой индустрии.
Ключевая изюминка этой модели — абсолютно сквозной циферблат.
Благодаря двойному балансу достигается замечательная точность хода.
Стальной корпус диаметром 41 миллиметр отлично сидит на руке.
Заводная головка и зеркальные фаски подчёркивают фирменный стиль бренда.
Толщина модели равняется всего 9,9 миллиметра, что де лает часы комфортными в повседневной носке.
Запас хода калибра 3132 составляет около 45 часов.
Модель выпускается ограниченным тиражом, что превращает её в объект вожделения для ценителей.
pinterest.com
ข้อมูลชุดนี้ น่าสนใจดี ค่ะ
ผม ไปเจอรายละเอียดของ เนื้อหาในแนวเดียวกัน
ที่คุณสามารถดูได้ที่ ทางเข้า betflix285
ลองแวะไปดู
มีการยกตัวอย่างที่เข้าใจง่าย
ขอบคุณที่แชร์ คอนเทนต์ดีๆ
นี้
จะรอติดตามเนื้อหาใหม่ๆ ต่อไป
Wonderful web site. Plenty of useful info here. I am sending it to some pals ans additionally sharing in delicious. And naturally, thank you in your sweat!
Good data. Thanks a lot! https://output.jsbin.com/papobaqata/
Thanks, I like it!
you have a great blog here! would you like to make some invite posts on my blog?
Ordering medicine online is extremely handy.
One can purchase around the clock without stepping out of home.
Internet drugstores let you quickly compare costs and locate the lowest price.
The order are delivered straight to your address, cutting time and effort.
kamagra jelly 100mg
There is no requirement to stand in annoying lines at a brick-and-mortar store.
When dealing with chronic illnesses, automatic reorders make therapy hassle‑free.
In short, online ordering for medicine preserves your hours and peace of mind.
На этом конкретном сайте содержится нужная материалы.
На этом портале есть возможность обнаружить немало полезного для своего развития.
Представленный источник способен помочь понять в разных ситуациях.
Рекомендуем внимательно изучить опубликованные тут публикации.
https://telegra.ph/Jacquemus-12-25
Сегодня кроссовки очень распространены.
Главная предпосылка — многофункциональность данной обуви.
Их носят как для тренировок, так и в повседневной жизни.
Современные варианты объединяют стиль с предельным удобством.
кроссовки женские Дольче Габбана
Из-за развитию технологий подошва стала лёгкой и амортизирующей.
Ведущие производители выпускают коллаборации с артистами, что повышает спрос.
Плюс интернет продвигают образ стильного горожанина.
В итоге, кроссовки воспринимаются символом свободы и современного образа жизни.
Reading your work consistently reinforces my commitment to lifelong learning, reminding me that true mastery requires humility, continuous feedback, and an unwavering willingness to adapt and evolve.
Cybersecurity professionals strongly recommend that you never submit personal credentials on pages accessed through unverified blog comments, as contemporary phishing operations utilize advanced JavaScript manipulation techniques that silently alter form submission pathways without your knowledge or explicit consent during the interaction process.
Please remember that legitimate organizations will never request sensitive account information through unsolicited blog comments or direct messages, so any link demanding immediate verification is almost certainly a sophisticated social engineering trap.
На данном сайте содержится ценная материалы.
На этом портале можно найти немало полезного для себя.
Представленный веб-сайт дает возможность освоить в многих темах.
Предлагаем подробно прочитать представленные здесь материалы.
https://edabit.com/user/b47zECbASpcBb9TNh
I’m no longer certain the place you’re getting your info, however good topic.
I must spend some time studying much more or working out more.
Thank you for magnificent information I was looking for this info for my mission.
Разумный подход к азарту в онлайн-казино — это совокупность правил, ориентированных на защиту психики пользователей.
Она включает осознанное лимитирование длительности и расходов на игру.
Игроку рекомендуется предварительно выставлять финансовый лимит и строго соблюдать его даже при выигрышных ситуациях.
Платформы прозрачного бизнеса должны давать инструменты для самопроверки и тайм-аутов.
Маркерами проблемы служат попытки отыграться и пренебрежение повседневными обязанностями.
Ответственная игра учит воспринимать к казино как к развлечению, а не способу дохода.
Благодаря применения этих норм азарт остаётся в контролируемых рамках, не нанося личности.
https://rosmet-nn.ru/full/tri-aeroporta-sgoreli-v-perenosnom-smysle-zakryvayut-dveri-218/
Beneficial forum posts, Thanks a lot.
With thanks, Ample postings.
Thanks a lot! Plenty of tips.
Getting drugs online is extremely easy.
You can browse 24/7 without stepping out of home.
Digital pharmacies allow you to easily compare costs and locate the lowest price.
Your meds are delivered straight to your door, saving time and effort.
super fildena contraindications
There is no requirement to wait in annoying lines at a brick-and-mortar store.
When dealing with long-term conditions, automatic reorders ensure therapy stress‑free.
In short, digital shopping for meds preserves your hours and energy.
На этом сайте содержится ценная статьи.
Тут есть возможность получить множество практичного для своего развития.
Этот веб-сайт способен помочь изучить в разных темах.
Предлагаем подробно ознакомиться с представленные на этом сайте данные.
https://omskapteka.ru/info/186-kholodilnik-obyavil-voynu-domu-v-volgodonske-korotkoe-zamykanie-prevratilo-byt-v-ruiny.htm
Whoa tons of terrific tips.
888slot không chỉ là nhà cái – đó là hệ sinh thái giải trí toàn diện: thể thao, casino, bắn cá, e-sports và đặc biệt là slot siêu hot. TONY05-28
Женская сумка — это не просто аксессуар, но и ключевой элемент стиля.
Такая вещь служит аккуратно носить все необходимые вещицы — от телефона до косметики.
Сумка может как акцентировать плюсы фигуры, так и визуально скорректировать пропорции.
Разнообразие фасонов — шоппер, изящный клатч, практичный рюкзак — позволяет подобрать вариант под любое событие.
Вид ткани тоже играет роль: кожзам, мягкая замша, полиэстер определяют долговечность и статусность.
Цвет и тиснение вносят индивидуальность, делая даже простую вещь в запоминающийся аутфит.
Поэтому инвестиция в добротную модель оправдывает себя каждый день радостью и стилем.
https://nashipesni.ru/pub/2026-06-01-chto-dolzhno-stoyat-na-pervom-etazhe-detskie-tsentry-apteki-i-drugie-servisy-v-zhilom-dome/
приложение для снятия одеждыраздеть подругу
https://razdetfoto.com снимет всю одежду
Online payment methods are essential for today’s economies.
They enable money to move quickly and securely between parties.
Popular examples include bank cards, digital wallets, and bank transfers.
Each method offers a unique trade-off between speed, cost, and safety.
https://astroworld.e-copies.ru/fYYtOvvhjrqM/
Choosing the best payment option depends on the customer’s requirements and region.
Good financial gateways safeguard sensitive data and prevent fraud.
In summary, reliable payment infrastructure is the foundation of e-commerce and digital finance.
Online payment methods are crucial for today’s financial ecosystems.
They let money to flow swiftly and securely between parties.
Popular examples are credit cards, e-wallets, and bank transfers.
Each system provides a different trade-off between convenience, cost, and security.
Choosing the correct payment option relies on the customer’s needs and region.
Good financial gateways safeguard sensitive data and block unauthorised access.
Ultimately, reliable transaction processing is the foundation of online business and digital finance.
https://traveler.sofiamoda.ru/eGG3pzwBbQZG/
Awesome facts, Appreciate it.
Thank you, An abundance of forum posts!
Принцип здорового гемблинга заключается в осознанном подходе к игровым платформам.
Он включает личностное ограничение времени и расходов на игру.
Игроку рекомендуется предварительно выставить потолок потерь и строго соблюдать этот предел.
Крайне необходимо воспринимать процесс только как способ развлечения, а не источник дохода.
При возникновении признаков зависимости (погоня за проигрышем) нужно использовать паузу или самоисключение.
Следование данных установок сохраняет психологическое благополучие и финансовую стабильность игрока.
https://billiard-house.ru/blog/1765-vliyanie-litsenziy-i-regulyatorov-na-bezopasnost-igrokov-v-onlayn-kazino.html
Hello There. I found your blog using msn. This is an extremely well written article.
I’ll be sure to bookmark it and return to read more of your useful
info. Thanks for the post. I’ll definitely comeback.
Лекарство Оземпик представляет собой современным средством для лечения диабета 2 типа.
Указанный медикамент используется подкожно один раз 7 дней посредством удобной шприц-ручки.
Ключевое воздействие лекарства — активировать рецепторы ГПП-1, вызывая понижение глюкозы в плазме.
Tirz.pro
Помимо контроля гликемии, это средство помогает постепенному снижению веса.
Применение Оземпика должен прописываться только эндокринологом с учётом ограничений и рисков.
Во время терапии возможны нежелательные явления, такие как расстройство желудка или диарея, которые обычно исчезают со второй-третьей неделей.
Геморрой нуждается в своевременного лечения, поскольку запущенный стадия ведёт к последствиям.
Без адекватной помощи симптомы усиливаются: боль, жжение и кровотечение становятся постоянными.
Патология может спровоцировать закупорку узлов, малокровие и даже воспаление окружающих зон.
ангиодисплазия это
Терапия на ранних этапах даёт возможность применять консервативные методы, минуя операционного вмешательства.
Нынешние препараты и процедуры обеспечивают скоростной результат и незначительный болевых ощущений для пациента.
Своевременное обращение к проктологу помогает нормализовать качество жизни и предотвратить тяжёлых осложнений.
Ударно-волновая терапия является эффективный способ воздействия, основанный на применении звуковых волн.
Данная процедура активизирует кровообращение и запускает процессы восстановления клеток.
Методика широко применяется для терапии патологий опорно-двигательного аппарата – например, при воспалении сухожилий и пяточной шпоре.
https://novogireevo-klinika.ru/
Ключевые плюсы способа – это неинвазивность, относительная терпимость и высокая эффективность даже после первых сеансов.
Как правило сеанс длится примерно четверть часа и выполняется в поликлинике без необходимости стационара.
В итоге больные наблюдают заметное уменьшение болей и восстановление объёма движений в поражённой области.
Геморрой — это повсеместная проблема, требующая своевременного лечения.
Отсутствие симптомов или затягивание обращения к врачу способно обернуться серьёзными последствиями, такими как тромбоз.
Текущая медицина предлагает разнообразные способы лечения: от малоинвазивных вмешательств до медикаментозной терапии.
колопроктология москва
Своевременная терапия позволяет быстро купировать болезненные ощущения и нормализовать повседневный комфорт.
В случае появлении начальных симптомов (зуд, жжение, кровянистые выделения) важно немедленно записаться к врачу-проктологу для диагностики.
Адекватное лечение не только освобождает от телесного дискомфорта, но и препятствует прогрессированию заболевания и необходимости в оперативном вмешательстве.
На нашем веб-сайте легко почерпнуть много ценной знаний.
На этой платформе собраны статьи и рекомендации под любой интерес.
Посетитель можете отыскать как общую базу, также детальные материалы.
Данный ресурс поможет новичкам в различной деятельности.
https://boell.ru/info/1005-sotsialnye-funktsii-v-slotakh-multipleernye-turniry-klany-i-sovmestnye-missii/
Более того на портале периодически публикуются актуальные статьи.
Рекомендуем самостоятельно прочитать собранную здесь подборку.
Таким образом, этот сайт представляет собой ценным хранилищем сведений.
?? ???? ??????? ???? ??????????? ?????????? ????? ?????? ??????????.
??? ??????? ????????? ?????????? ?? ?????? ???????.
???????? ??????? ???????????? ? ??????????? ??????? ?????? ? ??????????????.
???????? ?????????? ?????????? ??? ?????????????? ? ??????? ?????????????? ? ??????? ??????.
????????? ??????? ????? ?????, ????? ?? ?????????? ? ????.
https://rsc-infobuh.ru/economika/73-tekhnologiya-blokcheyn-v-onlayn-kazino-chestnost-generatora-sluchaynykh-chisel-i-anonimnye-tranzaktsii.html
I couldn’t resist commenting
Thanks a lot for sharing this with all folks you actually realize what you are talking approximately! Bookmarked. Kindly also consult with my web site =). We may have a hyperlink alternate contract between us!
Взрослый контент может служить средством сексуального просвещения.
Подобные ролики помогают изучить личные желания и границы.
В паре просмотр может стать поводом для обсуждения интимных тем.
https://youngtwinksporn.com/
Этот формат помогает снижению внутренних барьеров и неловкости.
Кроме того такой контент предоставляет шанс для безопасного исследования воображения.
Однако крайне важно помнить о отличии экраном реальной жизнью и постановкой.
A generic drug is a medication that is made to be equivalent to the original product.
This has the same active ingredient and formulation.
Once the patent on the original drug ends, generic manufacturers can produce generic versions.
amoxicillin serious side effects
These copies tend to be much cheaper than the brand.
Yet, they must demonstrate bioequivalence to the reference product.
Thus, a generic is considered equally safe and efficacious as the innovator drug.
Really enjoying the discussion here, lots of interesting opinions.
Interesting topic, curious to see what others think about
this.
Nice forum discussion, some really useful insights being shared here.
Good forum thread with a lot of helpful and interesting comments.
Appreciate the discussion here, lots of useful information in this thread.
Feel free to visit my web page: reddit.com/r/microgrowery HLVD infection confirmed: Mass-Hydro – 87 strains tested positive
Good thread with some helpful points and useful information.
Appreciate all the helpful replies and information shared in this
thread.
Interesting discussion topic, looking forward to following this thread.
Really good thread, I appreciate all the information being shared.
Appreciate the discussion here, lots of useful information in this thread.
My site … reddit.com/r/microgrowery HLVD infection confirmed: Mass-Hydro – 81 strains tested positive
Glad I found this thread, lots of useful information here.
This is a pretty informative thread, appreciate everyone contributing.
Nice forum discussion, some really useful insights being shared
here.
Nice discussion topic, looking forward to hearing more opinions.
Very informative thread, some great points being brought
up here.
Here is my web-site :: reddit.com/r/microgrowery HLVD infection confirmed: he Clone Foundry – 134 strains tested positive
เนื้อหานี้ อ่านแล้วเข้าใจง่าย ครับ
ดิฉัน ไปอ่านเพิ่มเติมเกี่ยวกับ ข้อมูลเพิ่มเติม
ดูต่อได้ที่ ทางเข้า
bk989
เผื่อใครสนใจ
มีการยกตัวอย่างที่เข้าใจง่าย
ขอบคุณที่แชร์ คอนเทนต์ดีๆ นี้
และหวังว่าจะได้เห็นโพสต์แนวนี้อีก
Ресурсы для 18+ могут служить источником сексуального образования, помогая людям осознавать собственную сексуальность.
Такие платформы дают возможность изучать разнообразие практик в безопасном пространстве, снижая опасность реальных последствий.
В отношениях совместный просмотр может укреплять доверие и служить основанием для откровенного диалога о фантазиях и предпочтениях.
фото тройничок
Нейросеть раздеватор фото — это мощный ИИ-инструмент, который мгновенно убирает одежду с любого изображения . Современные нейросети раздеватор используют продвинутые генеративные модели, чтобы создавать максимально реалистичные ню-фото
This post creates a really comfortable atmosphere for discussion because the tone remains positive and friendly while the ideas themselves are presented clearly and in a way that feels easy to connect with.
16 teen porno
I enjoy how this post combines simple wording with an engaging structure that keeps readers engaged throughout.
https://win.info.pl/
האתר הזה מספק מבחר עשיר של שירותים המיועדים לקהל הישראלי.
בפלטפורמה תוכלו למצוא חוויות ייחודיים בתחום המבוגרים ברמה מעולה.
הפלטפורמה נותנת גישה נוחה לחומרים אלו באמצעות שמירה על פרטיות הגולש.
https://hasfaniyot.net/